OCR(Optical Character Recongnition)即我们通常意义上讲的光学字符识别。在HALCON中,OCR常被用来分割区域及读取识别图像中的字符含义。
HALCON中提供了一组预先训练好的字体(在安装目录下的ocr文件夹中),这些字体来源于各个领域的大量训练数据,可识别文档、制药、工业产品或点打印,甚至手写数字文本。此外,HALCON还包括用于OCR-A和OCR-N的预训练字体,以及基于卷积神经网络(CNN)的通用字体。
18.1 OCR字符识别
使用HALCON提供的一种预训练字体读取图中的数字。

FontFile := 'Document_0-9_NoRej'
* 读取预训练字体Document_0-9_NoRej,由于没有指定文件扩展名,因此搜索具有MLP特定扩展名“.omc”或扩展名“.fnt”的文件。
read_ocr_class_mlp (FontFile, OCRHandle)
read_image (Image, 'numbers_scale')
threshold (Image, Region, 0, 125)
connection (Region, Characters)
count_obj (Characters, Number)
dev_set_color ('white')
for i := 1 to Number by 1
select_obj (Characters, SingleChar, i)
* 选择单个区域、原始图像和OCR句柄作为输入,最后返回最佳和第二佳的识别结果和置信度。
do_ocr_single_class_mlp (SingleChar, Image, OCRHandle, 2, Class, Confidence)
endfor18.2 图像分割
对于图像分割,可以使用的方法很多。常用的有Blob分析、自动文本阅读器、手动文本阅读器、通用字符分割等。
18.2.1 Blob分析
Blob分析包括设定有效ROI、图像滤波 (mean_image、gauss_filter、binomial_filter、median_image)、点状打印字符增强(dots_image)、灰度形态等。
(1)Example: hdevelop/Applications/OCR/engraved.hdev
此示例读取图中所示的金属表面上的雕刻文本。

通过使用Blob分析来分割图像:不能通过简单的阈值分割来提取字符。相反,简单的分割只能得到部分字符和产生大量噪声。使用灰度形态学预处理图像可以分割出真实字符。
gray_range_rect (Image, ImageResult, 7, 7) * 图像取反,字符识别默认为白色背景黑色字体 invert_image (ImageResult, ImageInvert) threshold (ImageResult, Region, 128, 255) connection (Region, ConnectedRegions) select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 1000,99999) sort_region (SelectedRegions, SortedRegions,'first_point','true','column') * 最后识别分割的区域结果 read_ocr_class_mlp (FontName, OCRHandle) for I := 1 to Number by 1 select_obj (SortedRegions, ObjectSelected, I) do_ocr_single_class_mlp (ObjectSelected, ImageInvert, OCRHandle, 1, Class, Confidence) endfor clear_ocr_class_mlp (OCRHandle)
(2)Example: hdevelop/Applications/OCR/ocrcolor.hdev
此示例提取表单中的字符。一个典型的问题是字符没有打印在正确的位置,如图所示。

由于字符打印在线上,不能简单的通过阈值分割来提取。因此这里通过字符颜色与表单颜色不同来分割图像,这里仅需考虑红色和绿色通道强度的差异。
threshold (Green, ForegroundRaw, 0, 220)
sub_image (RedReduced, GreenReduced, ImageSub, 2, 128)
mean_image (ImageSub, ImageMean, 3, 3)
binary_threshold (ImageMean, Cluster1, 'smooth_histo', 'dark', UsedThreshold)
difference (Foreground, Cluster1, Cluster2)
concat_obj (Cluster1, Cluster2, Cluster)
opening_circle (Cluster, Opening, 2.5)
* 使用形态学对所选像素进行处理
closing_rectangle1 (NumberRegion, NumberCand, 1, 20)
difference (Image, NumberCand, NoNumbers)
connection (NumberRegion, NumberParts)
intensity (NumberParts, Green, MeanIntensity, Deviation)
expand_gray_ref (NumberParts, Green, NoNumbers, Numbers, 20, 'image', MeanIntensity, 48)
union1 (Numbers, NumberRegion)
connection (NumberRegion, Numbers)
* 由于颜色的变化,因此不能使用背景的灰度值。人为生成一幅图像,将字符区域灰度值设为0,背景区域灰度值设为255。
paint_region (NoNumbers, Green, ImageOCRRaw, 255, 'fill')
paint_region (NumberRegion, ImageOCRRaw, ImageOCR, 0, 'fill')
* 在人工图像中执行实际的字符分类。
read_ocr_class_mlp ('Industrial_0-9_NoRej', OCRHandle)
do_ocr_multi_class_mlp (FinalNumbers, ImageOCR, OCRHandle, RecChar, Confidence)
clear_ocr_class_mlp (OCRHandle)18.2.2 自动文本阅读器
自动文本阅读器非常易于使用,它将分割和识别两个步骤组合成find_text的一个调用,且无需进行大量的参数调整。simple_reading.hdev和bottle.hdev为熟悉自动文本阅读器提供了一个很好的起点。
要使用自动文本阅读器,必须使用create_text_model_reader创建模型,并将参数Mode设置为'auto'。在这里,必须传递OCR分类器参数。然后可以使用set_text_model_param指定分割参数,并可以使用get_text_model_param查询。完成后,可以使用find_text读取文本。该算子根据区域和灰度值特征选择候选字符,并使用给定的OCR分类器对其进行验证。
如果文本必须匹配某个模式或结构,则可以设置运算符set_text_model_param的参数'text_line_structure',它确定结构,即要检测的文本的每个字符块的字符数。
自动文本阅读器假定文本方向大致水平。如果文本未水平对齐,则可以在使用find_text之前使用text_line_orientation和rotate_image矫正方向。
find_text的结果在TextResultID中返回,可以分别使用get_text_result和get_text_object查询。get_text_result返回分类结果。get_text_object返回自动文本阅读器分割的字符区域。要删除结果和文本模型,需分别使用clear_text_result和clear_text_model。
(1)Example: solution_guide/basics/simple_reading.hdev
此示例程序演示了如何使用预训练的OCR字体使用自动文本阅读器识别简单字符。
* 使用create_text_model_reader创建模型,并将参数Mode设置为'auto'。
create_text_model_reader('auto','Document_09_NoRej',TextModel)
find_text (Image, TextModel, TextResultID)
get_text_result (TextResultID, 'class', Classes)(2)Example: hdevelop/Applications/OCR/bottle.hdev
这个例子读取图中瓶子上的日期。

由于图像中可见大量文本,因此需要设置文本模型的一些参数以适当地限制读取结果。
FontName := 'Universal_0-9_NoRej'
create_text_model_reader ('auto', FontName, TextModel)
* 增加最小笔划宽度以排除日期周围可见的所有文本
set_text_model_param (TextModel, 'min_stroke_width', 6)
* 设置日期的已知结构以确保仅读取与该结构匹配的文本
set_text_model_param (TextModel, 'text_line_structure', '2 2 2')
*
find_text (Bottle, TextModel, TextResultID)
* 显示分割结果
get_text_object (Characters, TextResultID, 'all_lines')
* 显示读取结果
get_text_result (TextResultID, 'class', Classes)18.2.3 手动文本阅读器
如果要分割雕刻文本或者不能提供合适的OCR分类器,则不能使用自动文本阅读器。相反,可以在这些情况下使用手动文本阅读器。
要使用手动文本阅读器,必须使用create_text_model_reader创建模型,并将参数Mode设置为'manual'。需注意,在这种情况下,不能传递OCR分类器。可以与Manual Text Finder一起使用的所有参数的名称都以'manual_'开头。
(1)Example: hdevelop/Applications/OCR/find_text_dongle.hdev
此示例演示如何在执行OCR之前使用find_text对加密狗上的点打印字符进行分割。

read_image (Image, 'ocr/dongle_01')
* 读取OCR分类器文件
read_ocr_class_mlp ('DotPrint_NoRej', OCRHandle)
* 创建文本模型并指定文本属性
create_text_model_reader ('manual', [], TextModel)
set_text_model_param (TextModel, 'manual_char_width', 24)
set_text_model_param (TextModel, 'manual_char_height', 33)
set_text_model_param (TextModel, 'manual_is_dotprint', 'true')
set_text_model_param (TextModel, 'manual_max_line_num', 2)
set_text_model_param (TextModel, 'manual_return_punctuation', 'false')
set_text_model_param (TextModel, 'manual_return_separators', 'false')
set_text_model_param (TextModel, 'manual_stroke_width', 4)
set_text_model_param (TextModel, 'manual_eliminate_horizontal_lines', 'true')
* 定义文本行结构,''6 1 8'意味着该文本具有由6个,1个和8个字符组成的三个块。为了定义多个结构,可以将索引号添加到参数名称。对于第二行,定义了两个结构,因为有时'/'被分类为分隔符,有时会被分类为字符。
set_text_model_param (TextModel, 'manual_text_line_structure_0', '6 1 8')
set_text_model_param (TextModel, 'manual_text_line_structure_1', '8 10')
set_text_model_param (TextModel, 'manual_text_line_structure_2', '19')
* 为了增加字符识别的准确性,定义了正则表达式,稍后将由do_ocr_word_mlp使用。
TextPattern1 := '(FLEXID[0-9][A-Z][0-9]{3}[A-F0-9]{4})'
TextPattern2 := '([A-Z]{3}[0-9]{5}.?[A-Z][0-9]{4}[A-Z][0-9]{4})'
Expression := TextPattern1 + '|' + TextPattern2
NumImages := 8
for I := 1 to NumImages by 1
read_image (Image, 'ocr/dongle_' + I$'02')
* 图像预处理,缩减区域范围。使用scale_image_max改善对比度并且旋转图像使字符呈水平。
binary_threshold (Image, Region, 'max_separability', 'dark', UsedThreshold)
opening_rectangle1 (Region, RegionOpening, 400, 50)
erosion_rectangle1 (RegionOpening, RegionOpening, 11, 11)
connection (RegionOpening, ConnectedRegions)
select_shape_std (ConnectedRegions, SelectedRegion, 'max_area', 70)
reduce_domain (Image, SelectedRegion, ImageReduced)
scale_image_max (ImageReduced, ImageScaleMax)
text_line_orientation (SelectedRegion, ImageScaleMax, 30, rad(-30), rad(30), OrientationAngle)
rotate_image (ImageScaleMax, ImageRotate, deg(-OrientationAngle), 'constant')
* 查找文本并显示每个分割区域的结果
find_text (ImageRotate, TextModel, TextResult)
get_text_result (TextResult, 'manual_num_lines', NumLines)
dev_display (ImageRotate)
for J := 0 to NumLines - 1 by 1
get_text_object (Line, TextResult, ['manual_line',J])
* OCR使用正则表达式更准确地读取文本。
do_ocr_word_mlp (Line, ImageRotate, OCRHandle, Expression, 3, 5, Class, Confidence, Word, Score)
* 显示结果
smallest_rectangle1 (Line, Row1, Column1, Row2, Column2)
count_obj (Line, NumberOfCharacters)
dev_set_colored (6)
dev_display (Line)
dev_set_color ('white')
for K := 1 to NumberOfCharacters by 1
select_obj (Line, Character, K)
set_tposition (WindowHandle, Row2[0] + 4, Column1[K - 1])
write_string (WindowHandle, Word{K - 1})
endfor
endfor
if (I < NumImages)
disp_continue_message (WindowHandle, 'black', 'true')
stop ()
endif
clear_text_result (TextResult)
endfor
clear_text_model (TextModel)
clear_ocr_class_mlp (OCRHandle)18.2.4 普通字符分割
对于普通字符分割,可以使用segment_characters获取包含所有候选字符的区域,然后应用select_characters选择区域中单个字符的那些部分。或者使用blob分析,最简单的方法是阈值分割。另一种非常常见的方法是dyn_threshold。
(1)Example: hdevelop/OCR/Segmentation/select_characters.hdev
此示例显示如何使用专为OCR提供的分割运算符轻松分割点打印的旋转字符。

read_image (Image, 'dot_print_rotated/dot_print_rotated_' + J$'02d') * 确定文本行的方向,旋转图像,使得字符呈水平方向 text_line_orientation (Image, Image, 50, rad(-30), rad(30), OrientationAngle) rotate_image (Image, ImageRotate, -OrientationAngle / rad(180) * 180, 'constant') * * 应用segment_characters和select_characters分割完整的打印区域,然后选择区域中作为单个字符候选的那些部分。与使用Blob分析的经典分割相比,这里找到了各个字符的区域,尽管它们仍然由未连接的小区域组成。 segment_characters (ImageRotate, ImageRotate, ImageForeground, RegionForeground, 'local_auto_shape', 'false', 'true', 'medium', 25, 25, 0, 10, UsedThreshold) select_characters (RegionForeground, RegionCharacters, 'true', 'ultra_light', 60, 60, 'false', 'false', 'none', 'true', 'wide', 'true', 0, 'completion')
18.2.5 基于语法和词典的OCR结果自动校正
(1)Example: hdevelop/OCR/Neural-Nets/label_word_process_mlp.hdev
此示例读取图中描述的"best before"日期。要纠正第一文本行OCR的错误识别结果,需使用基于词典的自动校正。例如,由于字符的相似性,在字符O和数字0之间可能发生错误。对于第二文本行,使用正则表达式来确保结果具有正确的格式。

首先,读取预训练字体Industrial作为实际OCR。对于文本的上一行,三个预期单词存储在使用create_lexicon创建的词典中,稍后将使用。然后,读取图像,生成并对齐用于打印的ROI,并且使用Blob分析提取字符的区域并将其存储在变量SortedWords中。
* 这个示例展示了如何通过使用正则表达式或允许词典限制的结果来改进OCR结果。注意,为了演示的目的,分类结果被人为地扭曲了。
read_image (Image, 'label/label_01.png')
read_ocr_class_mlp ('Industrial_NoRej', OCRHandle)
* 创建3个单词的词典
create_lexicon ('label', ['BEST','BEFORE','END'], LexiconHandle)
for i := 1 to 9 by 1
read_image (Image, 'label/label_0' + i + '.png')
threshold (Image, Region, 128, 230)
connection (Region, ConnectedRegions)
select_shape (ConnectedRegions, LabelRaw, 'width', 'and', 350, 450)
opening_circle (LabelRaw, LabelOpen, 5)
shape_trans (LabelOpen, Label, 'rectangle2')
* 旋转文本方向
text_line_orientation (Label, Image, 25, -0.523599, 0.523599, OrientationAngle)
hom_mat2d_identity (HomMat2DIdentity)
hom_mat2d_rotate (HomMat2DIdentity, -OrientationAngle, 0, 0, Deskew)
affine_trans_image (Image, ImageDeskew, Deskew, 'constant', 'false')
affine_trans_region (Label, LabelDeskew, Deskew, 'nearest_neighbor')
smallest_rectangle1 (LabelDeskew, LabelTop, LabelLeft, LabelBottom, LabelRight)
reduce_domain (ImageDeskew, LabelDeskew, ImageOCR)
* 提取特征区域
var_threshold (ImageOCR, Foreground, 40, 40, 0.8, 10, 'dark')
connection (Foreground, Blobs)
partition_dynamic (Blobs, Split, 21, 40)
select_shape (Split, Characters, ['width','height'], 'and', [10,20], [30,50])
select_shape (Characters, CharactersWords, 'row', 'and', 0, LabelTop + 80)
select_shape (Characters, CharactersDate, 'row', 'and', LabelTop + 80, 600)
* 人为地扭曲分割结果以示范校正效果
move_region (CharactersWords, CharactersWords, 0, 3)
move_region (CharactersDate, CharactersDate, -2, 0)
* 处理文本
sort_region (CharactersWords, SortedWords, 'character', 'true', 'row')
area_center (SortedWords, Area, Row, Column)
Column[|Column|] := 9999
gen_empty_obj (Word)
Text := ''
OriginalText := ''
for j := 1 to |Column| - 1 by 1
select_obj (SortedWords, Character, j)
concat_obj (Word, Character, Word)
* 检查字符间距以确定单词的结尾
if (j == |Column| or (Column[j] - Column[j - 1]) > 30)
* 不使用基于词典的自动校正识别单词(用于比较)
do_ocr_word_mlp (Word, ImageOCR, OCRHandle, '.*', 1, 5, Class, Confidence, WordText, WordScore)
OriginalText := OriginalText + ' ' + WordText
* 基于词典校正的单词识别
do_ocr_word_mlp (Word, ImageOCR, OCRHandle, '<label>', 1, 5, Class, Confidence, WordText, WordScore)
Text := Text + ' ' + WordText
gen_empty_obj (Word)
endif
endfor
sort_region (CharactersDate, SortedDate, 'character', 'true', 'row')
* 不受限制地对数据字符串进行分类(用于比较)
do_ocr_word_mlp (SortedDate, ImageOCR, OCRHandle, '.*', 5, 5, Class, Confidence, OriginalDateText, DateScore)
* 使用正则表达式对数据字符串进行分类
do_ocr_word_mlp (SortedDate, ImageOCR, OCRHandle, '^([0-2][0-9]|30|31)/(0[1-9]|10|11|12)/0[0-5]$', 10, 5, Class, Confidence, DateText, DateScore)
if (i < 9)
set_display_font (WindowHandle, 14, 'mono', 'true', 'false')
disp_continue_message (WindowHandle, 'black', 'true')
set_display_font (WindowHandle, 20, 'mono', 'true', 'false')
endif
stop ()
endfor
clear_lexicon (LexiconHandle)
clear_ocr_class_mlp (OCRHandle)18.3 自定义OCR分类器
18.3.1 训练OCR
下图显示了训练文件生成的过程:首先,必须使用分割方法提取样本图像中的字符(参见上文)。必须为每个单个字符分配一个标签,通过编入输入或者从文件中读取字符标签来完成。然后,将这些区域及其标签写入训练文件中(append_ocr_trainf)。在进行训练之前,检查训练文件的正确性。通过使用与可视化运算符结合的read_ocr_trainf来实现。

注意,还可以训练自己的系统字体。通过改变和扭曲字符的字体,可以增加每个类的不同训练样本的数量,从而提高检测率。为此,可以使用HDevelop的OCR Assistant的训练文件工具箱。此外,示例程序generate_system_font.hdev还显示了如何从系统字体派生训练数据和OCR分类器。
实际训练如图所示。首先,创建一个新的分类器。有四种不同的OCR分类器:神经网络(多层感知器MLP)分类器,基于支持向量机(SVM)的分类器,基于k近邻方法(k-NN)的分类器,以及box分类器。

注意,如果要使用自动文本阅读器进行文本的分割和分类,则必须提供基于MLP的OCR分类器。当只有少量样本可用时,k-NN具有优势,但在典型的OCR应用中, MLP和SVM的性能优于k-NN。因此,仅进一步介绍MLP和SVM。
两个分类器的不同之处如下:MLP分类器在分类上更快,但是对于大型训练集其训练速度较慢(与基于SVM的分类器相比)。如果训练可以离线应用,时间不是关键因素,MLP是一个不错的选择。基于SVM的分类器比MLP分类器具有更好的识别率,并且在训练时更快(特别是对于大型训练集)。但是,与MLP分类器相比,分类过程需要消耗更多时间。
根据所选分类器,使用create_ocr_class_mlp或create_ocr_class_svm创建分类器。然后,使用trainf_ocr_class_mlp或trainf_ocr_class_svm应用训练。在训练之后,通常将分类器保存到磁盘以供以后使用(write_ocr_class_mlp或write_ocr_class_svm)。
18.3.2 识别字符
下图显示了分类过程。首先,必须使用适当的分割方法提取字符。从文件(read_ocr_class_mlp或read_ocr_class_svm)读取分类器(字体文件)后,分类器可用于识别。自动文本阅读器只需一步即可完成分割和分类两个步骤。

将多个字符传递给读取算子(do_ocr_multi_class_mlp或do_ocr_multi_class_svm)。这里,对于每个区域,返回相应的标签和置信度。有时,不仅要获得置信度最高的字符,还要获得置信度较低的其它字符。例如,0可能容易被误认为字母 “O”。算子do_ocr_single_class_mlp和do_ocr_single_class_svm返回此信息。
最后一步,需要将数字或字符组成字符串。这可以通过区域处理运算符来实现。
此外,HALCON还为基于语法和词典的自动校正提供运算符。例如,可以使用do_ocr_word_mlp而不是do_ocr_multi_class_mlp来查找与正则表达式匹配的字符集,即存储在词典中的字符集,这些词典由create_lexicon创建或由import_lexicon导入。
18.3.3 生成训练文件
Example: solution_guide/basics/gen_training_file.hdev
下图显示了一个训练图像,第三行中的字符用作训练样本。对于此示例图像,分割非常简单,因为字符明显比背景暗。因此,可以使用阈值分割。

用于训练的字符行数由变量TrainingLine指定。要选择此行,首先使用closing_rectangle1将字符组合成水平行。然后通过connection将这些行转换为其连通域。在所有行中,使用select_obj选择相对应的行。通过将原始分割和所选行的交集作为输入,返回训练的字符。使用sort_region从左到右排序。
TrainingLine := 3 threshold (Image, Region, 0, 125) closing_rectangle1 (Region, RegionClosing, 70, 10) connection (RegionClosing, Lines) select_obj (Lines, Training, TrainingLine) intersection (Training, Region, TrainingChars) connection (TrainingChars, ConnectedRegions) sort_region (ConnectedRegions, SortedRegions, 'first_point', 'true', 'column')
现在,字符可以存储在训练文件中。作为准备步骤,删除可能存在的较旧训练文件。在所有字符的循环内,选择单个字符。变量Chars包含字符的标签Tuple。使用append_ocr_trainf将选定的区域以及图像和相应的标签添加到训练文件中。
Chars := ['0','1','2','3','4','5','6','7','8','9']
TrainFile := 'numbers.trf'
dev_set_check ('~give_error')
delete_file (TrainFile)
dev_set_check ('give_error')
for i := 1 to 10 by 1
select_obj (SortedRegions, TrainSingle, i)
append_ocr_trainf (TrainSingle, Image, Chars[i - 1], TrainFile)
endfor18.3.4 创建和训练OCR分类器
Example: solution_guide/basics/simple_training.hdev
准备好训练文件后,OCR分类器的创建和训练非常简单。首先,确定训练文件和最终字体文件的名称。建议使用“.trf”作为训练文件。对于OCR分类器,建议对box分类器使用“.obc”(不再推荐使用),对于神经网络分类器使用“.omc”,对于基于支持向量机使用 “.osc”。如果在读取过程中没有指定扩展名,则对于box或神经网络分类器,还会搜索扩展名为“.fnt”的文件,这两个分类器在早期HALCON版本中都很常见。
要创建OCR分类器,需要确定一些参数。最重要的是所有标签的名称列表。可以使用read_ocr_trainf_names从训练文件中轻松提取此列表。
TrainFile := 'numbers.trf' read_ocr_trainf_names (TrainFile, CharacterNames, CharacterCount)
另一个重要参数是神经网络隐藏层中的节点数。在这里,它被设置为20。根据经验,该数字应该与标签的数量相同。除了这两个参数之外,其它参数选用默认值用于create_ocr_class_mlp。使用trainf_ocr_class_mlp进行训练,参数也使用默认值。
NumHidden := 20 create_ocr_class_mlp (8, 10, 'constant', 'default', CharacterNames, NumHidden, 'none', 1, 42, OCRHandle) trainf_ocr_class_mlp (OCRHandle, TrainFile, 200, 1, 0.01, Error, ErrorLog) * 最后,将分类器(字体文件)存储到磁盘并释放内存。 FontFile := 'numbers.omc' write_ocr_class_mlp (OCRHandle, FontFile) clear_ocr_class_mlp (OCRHandle)
注意,对于更复杂的OCR分类器,尤其是训练数据包含非常嘈杂和变形的样本,则建议创建权重正则化的基于MLP的OCR分类器(参见set_regularization_params_ocr_class_mlp)。这增强了分类器的泛化能力并且防止对单个训练样本的过度拟合。
如果为自动文本阅读器创建了OCR分类器,建议另外使用set_rejection_params_ocr_class_mlp定义拒绝类,这有助于区分字符与复杂的背景。
18.3.5 具有正则权重和拒绝类的OCR分类器
也可以创建和训练具有正则权重和拒绝类的分类器。
正则权重可以提升分类性能:
• 如果未经正则的MLP出错,则错误结果的置信度通常会非常高。
• 如果正则化的MLP出错,则返回直观的置信度。能表明更好的泛化能力。
可以使用运算符设置和查询正则化的参数
• set_regularization_params_ocr_class_mlp和
• get_regularization_params_ocr_class_mlp
如何设置用于创建和训练具有正则化的分类器的参数,如以下HDevelop示例所示:
• 示例regularized_ocr_mlp.hdev创建具有严重失真的测试样本,这些失真程度远远超出训练失真的范围,以测试MLP和正则化MLP的泛化能力。
• 示例class_mlp_regularization.hdev显示了使用MLP规范二维数据的效果。
拒绝类可能是有用的,因为它返回图像中无法成功读取的符号,因为它们不是符号,有可能是噪声,或者是其它存在的问题。
可以使用运算符设置和查询拒绝类的参数
• set_rejection_params_ocr_class_mlp和
• get_rejection_params_ocr_class_mlp。
示例程序set_rejection_params_class_mlp.hdev显示了如何使用MLP的拒绝类来分类二维数据。
18.4 扩展内容
18.4.1 组合符号
一些字符和符号由多个子符号组成,如“i”,“%”或“!”。对于OCR,这些子符号必须组合成单个区域。如果使用segment_characters和select_characters进行字符分割,则会自动组合子符号。否则,就需要通过在阈值处理后调用closing_rectangle1来组合它们,结构元素通常使用较小的宽度和较大的高度。在调用connection以分割字符后,使用intersection来获取原始分割(输入参数2),同时输入connection中的连通域(输入参数1)。
18.4.2 圆形打印字符
在某些情况下,符号不是水平打印的,而是沿着圆弧打印,例如在CD上打印。为了读取它们,提取相应圆的(虚拟)中心和半径。使用polar_trans_image_ext展开图像。要将在展开的图像中获得的区域投影回原始图像,可以使用polar_trans_region_inv。
18.4.3 OCR 特征
HALCON为OCR提供了许多不同的功能,其中大部分仅供高级使用。在大多数情况下,建议使用功能组合“default”。此组合基于字符周围矩形内的灰度值。在不能使用字符的背景的情况下,例如,如果它因纹理而变化,则特征'pixel_binary','ratio'和'anisometry'是良好的组合。这里,仅使用区域,忽略基础灰度值。
18.5 预训练的ORC字体
以下部分将简要介绍HALCON提供的预训练OCR字体。可以在安装HALCON的文件夹的子目录ocr中访问它们。预训练字体是使用在亮背景下的暗字符进行训练的。如果要使用提供的字体读取暗背景下的亮字符,可以使用invert_image反转图像,如果效果不好,则可以应用gen_image_proto设为浅灰色值,然后overpaint_region将灰度值设置为0来预处理图像。
预训练字体是使用编码Windows-1252的字符进行训练的。因此,ASCII代码大于127的字符符号('e','£','¥')的外观可能与预期的外观不同,具体取决于系统的字符编码。在这种情况下,应根据其ASCII码检查分类字符,即'e'为128,'£'为163,'¥'为165。
18.5.1 具有正则权重和拒绝类的预训练字体
所有预训练的OCR字体都有两个版本。以_NoRej结尾的字体名称具有正则化权重但没有拒绝类,以_Rej结尾的字体名称具有正则化权重及拒绝类。由于正则化,预训练的OCR字体提供了更有意义的置信度。使用拒绝类的字体,可以区分字符与杂乱背景。带有拒绝类的字体返回ASCII Code 26。
18.5.2 即用型OCR字体的命名法
OCR字体的内容由其名称描述。名称以组名开头,例如Document或DotPrint,后跟OCR字体中包含的符号集的指示符。指标的含义如下:
• 0-9:OCR字体包含数字0到9。
• A-Z:OCR字体包含大写字符A到Z.
• +:OCR字体包含特殊字符。特殊字符列表与单个OCR字体略有不同。
• _NoRej:OCR字体没有拒绝类。
• _Rej:OCR字体有拒绝类。
如果OCR字体的名称不包含任何上述指示符或仅后跟指示符_NoRej或_Rej,通常,OCR字体包含数字0到9,大写字符A到Z,小写字符a到 z,和特殊字符。某些OCR字体不包含小写字符(例如,DotPrint)。
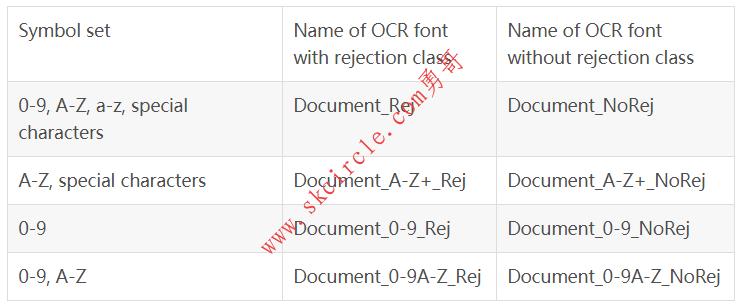
18.5.3 预训练字体’Document’
’Document’可用于读取以Arial,Courier或Times New Roman等字体打印的字符。这些是用于打印文档或字母的典型字体。请注意,无法区分字体Arial的字符I和l。这意味着l可能被误认为是I,反之亦然。
可用的特殊字符:- = + < > . # $ % & ( ) @ * e £ ¥
18.5.4 预训练字体 ’DotPrint’
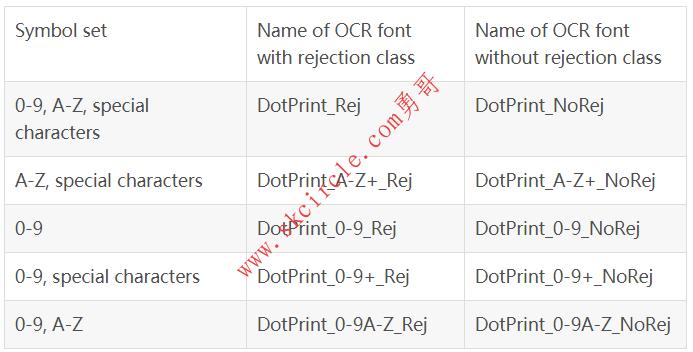
‘DotPrint’可用于读取用点式打印机打印的字符。它不包含小写字符。
可用的特殊字符:- / . * :

18.5.5 预训练字体 ’HandWritten_0-9’
‘HandWritten_0-9’可用于读取手写数字。它包含数字0-9。
可用的特殊字符:无


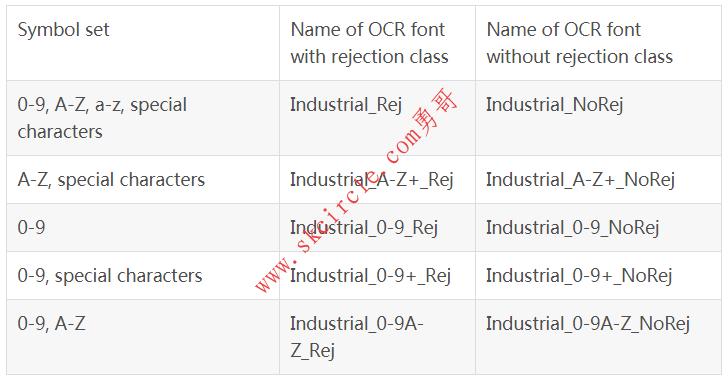
18.5.6 预训练字体 ’Industrial’
‘Industrial’可用于读取以Arial,OCR-B或其他sans-serif字体等打印的字符。例如,这些字体通常用于打印标签。
可用的特殊字符:- / + . $ % * e £ ¥

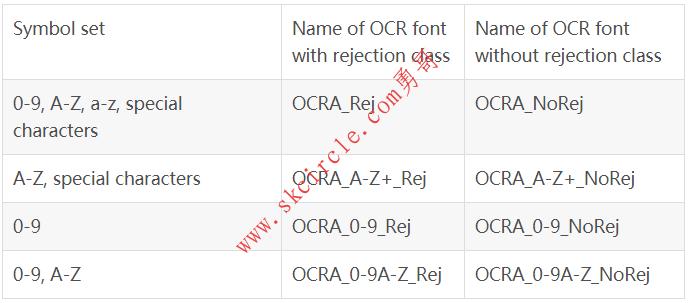
18.5.7 预训练字体 ’OCR-A’
‘OCR-A’可用于读取以字体OCR-A打印的字符。
可用的特殊字符: - ? ! / \{} = + < > . # $ % & ( ) @ * e £ ¥

18.5.8 预训练字体 ’OCR-B’
‘OCR-B’可用于读取以字体OCR-B打印的字符。
可用的特殊字符:- ? ! / \{} = + < > . # $ % & ( ) @ * e £ ¥
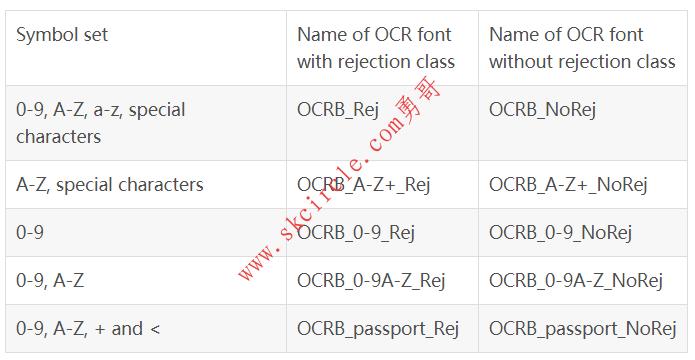

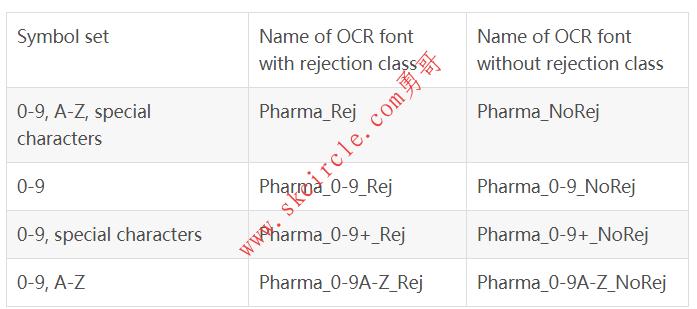
18.5.9 预训练字体 ’Pharma’
‘Pharma’可用于读取以Arial,OCR-B等字体打印的字符,以及制药行业通常使用的其它字体(见图18.18)。此OCR字体不包含小写字符。
可用的特殊字符: - / . ( ) :

18.5.10 预训练字体 ’SEMI’
‘SEMI’可用于读取以SEMI字体打印的字符,该字体由易于彼此区分的字符组成。它有一组有限的字符,可以在图18.19中看到。此OCR字体不包含小写字符。
可用的特殊字符: - .


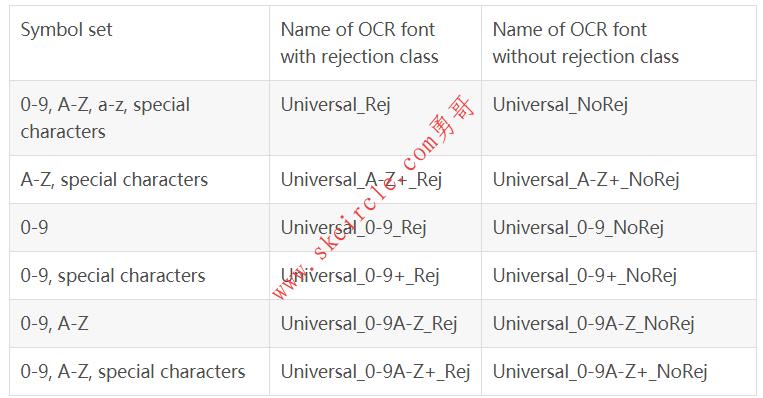
18.5.11 预训练字体 ’Universal’
‘Universal’可用于读取各种不同的字符。这种基于CNN训练的字体的基于 ‘’Document’,“DotPrint”,“SEMI”和“Industrial’”等字符。
可用的特殊字符:- / = + : < > . # $ % & ( ) @ * e £ ¥

————————————————
版权声明:本文为CSDN博主「Mr.Devin」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/IntegralforLove/article/details/83756956