少有人走的路
少有人走的路哈哈,是不是有人一进来就想问训练数据哪找的。。
好吧,坐好,老司机要发车了,传送门—->用 Caffe 可以做什么好玩的 Project?,其实就是知乎上前两天看到的一个问题,有人提供了这个数据集,大家有兴趣的可以自己下下来看看,我这里就不贴了,怕被河蟹。。
总之就是有10000张正常电影封面+10000张av电影封面,正好这几天临近放假,project/assignment什么的都搞完了,离回家还有几天,呆实验室打了好几天游戏也挺无聊了,便花了一下午训练了这个网络,在天朝有鉴黄师的话,那这个就叫监黄器咯,确实百度还有很多直播平台早就已经有这种功能的机器了。。最近雅虎也开源了一个他们训练的监黄网络,yahoo/open_nsfw也是基于caffe框架的,也挺有趣的,过两天有时间可以git下来看看,可以百度相关资料~OpenCV实践之路——雅虎色情图片检测神经网络试用报告, 不过就别问训练数据从哪找了,不会有答案的。。
老司机的话,对于这种体量的数据集,还是二分类,肯定嗤之以鼻,不屑一顾,很简单的事。所以对于我这种新人来说,这里也只是作为练习和记录而已,分享一些遇到过的问题,希望对看到的人有帮助而已,并没有其他博客那种教大家什么“xx系列”“xx教程”“xx第n天”的想法。
好了,那么我的想法很简单,9000张av+9000张正常的作为训练集,剩下1000张av+1000张正常作为验证集,(虽然并没有做参数的验证,最后直接找图片测试了)。使用caffe自带的caffemodel,基于AlexNet模型的,稍微改了几个参数,就是几个卷积核的大小,因为数据集小,图片分辨率(160*120)也小,分类少,所以太多参数没意义。接下来就是顺着caffe官网Tutorial的步骤一步步实现就好了。
转换数据格式
首先原始数据集图像的命名挺乱的,一个imgs_n(normal)文件夹,一个imgs_p(porn)文件夹,分别有10000张图片,如下图,
我就用脚本统一了一下,重命名加移动一起做了,用脚本实现还是挺方便的
#!/bin/bash filelist=`ls /home/zfq/ero/imgs_n` i=1 for file in $filelist do fileName=/home/zfq/ero/imgs_n/$file #我胆小一直喜欢用绝对地址 newFileName=/home/zfq/ero/ero_train/$i.jpg mv $fileName $newFileName let i=i+1 done
其余同理,大概也就两三个脚本互相move好了,这样以后av从1-10000.jpg,正常的从10001-20000.jpg,且前9000分别被移到train文件夹,后1000被移到test文件夹中
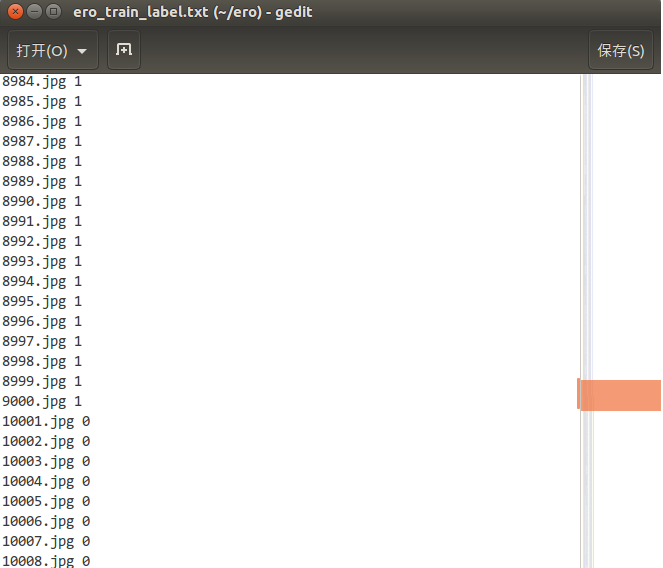
2. 然后用脚本生成对应的label文件,如果是nsfw(not safe for work)就标记为1,否则为0,shell脚本如下:
#!/bin/bash
l=.jpg\ 1
for (( i=9001; i<=10000; i++ ))
do
label=$i$l
echo $label >> test_label.txt
done
s=.jpg\ 0
for (( i=19001; i<=20000; i++ ))
do
label=$i$s
echo $label >> test_label.txt
done
test_labl同理
3. 生成lmdb格式数据集
#!/bin/bash
DATA=/home/zfq/ero
rm -rf $DATA/img_train_lmdb
/home/zfq/caffe/build/tools/convert_imageset --shuffle \
$DATA/ero_train/ $DATA/train_label.txt $DATA/img_train_lmdb
#测试数据不用--shuffle,我吃过一次亏,当时纠结好久
/home/zfq/caffe/build/tools/convert_imageset \
$DATA/ero_test/ $DATA/test_label.txt $DATA/img_test_lmdb
执行后生成的两个lmdb文件夹:
4. 生成图像均值
命令为:
#!/usr/bin/env sh
/home/zfq/caffe/build/tools/compute_image_mean /home/zfq/ero/img_train_lmdb \
/home/zfq/ero/ero_img_mean.binaryproto
echo "Done."
执行后生成了图像均值的二进制文件ero_img_mean.binaryproto
开始训练
就直接命令行/home/zfq/caffe/build/tools/caffe train -solver /home/zfq/ero/ero_solver.prototxt,运行过程:
I0113 16:14:14.618067 12061 caffe.cpp:218] Using GPUs 0 I0113 16:14:14.737269 12061 caffe.cpp:223] GPU 0: GeForce GTX 1060 6GB I0113 16:14:15.705453 12061 solver.cpp:48] Initializing solver from parameters: test_iter: 40 test_interval: 1000 base_lr: 0.001 display: 100 max_iter: 50000 lr_policy: "step" ... } I0113 16:14:15.705597 12061 solver.cpp:91] Creating training net from net file: /home/zfq/ero/ero_train_val.prototxt ... I0113 16:14:15.731236 12061 net.cpp:58] Initializing net from parameters: name: "eroNet" ... ... ...... I0113 16:14:15.732077 12061 layer_factory.hpp:77] Creating layer data I0113 16:14:15.733901 12061 net.cpp:100] Creating Layer data I0113 16:14:15.733943 12061 net.cpp:408] data -> data I0113 16:14:15.733999 12061 net.cpp:408] data -> label I0113 16:14:15.734037 12061 data_transformer.cpp:25] Loading mean file from: /home/zfq/ero/ero_img_mean.binaryproto I0113 16:14:15.735918 12070 db_lmdb.cpp:35] Opened lmdb /home/zfq/ero/img_train_lmdb I0113 16:14:16.454490 12061 data_layer.cpp:41] output data size: 256,3,160,120 I0113 16:14:16.542208 12061 net.cpp:150] Setting up data I0113 16:14:16.542276 12061 net.cpp:157] Top shape: 256 3 160 120 (14745600) I0113 16:14:16.542284 12061 net.cpp:157] Top shape: 256 (256) I0113 16:14:16.542289 12061 net.cpp:165] Memory required for data: 58983424 I0113 16:14:16.542304 12061 layer_factory.hpp:77] Creating layer conv1 I0113 16:14:16.542330 12061 net.cpp:100] Creating Layer conv1 ... I0113 16:14:19.045210 12061 net.cpp:100] Creating Layer loss I0113 16:14:19.045213 12061 net.cpp:434] loss <- fc8 I0113 16:14:19.045231 12061 net.cpp:434] loss <- label I0113 16:14:19.045238 12061 net.cpp:408] loss -> loss I0113 16:14:19.045248 12061 layer_factory.hpp:77] Creating layer loss I0113 16:14:19.065199 12061 net.cpp:150] Setting up loss I0113 16:14:19.065220 12061 net.cpp:157] Top shape: (1) I0113 16:14:19.065223 12061 net.cpp:160] with loss weight 1 I0113 16:14:19.065258 12061 net.cpp:165] Memory required for data: 2423458820 I0113 16:14:19.065276 12061 net.cpp:226] loss needs backward computation. I0113 16:14:19.065295 12061 net.cpp:226] fc8 needs backward computation. I0113 16:14:19.065299 12061 net.cpp:226] drop7 needs backward computation. ... I0113 16:14:19.065440 12061 net.cpp:226] conv1 needs backward computation. I0113 16:14:19.065444 12061 net.cpp:228] data does not need backward computation. I0113 16:14:19.065448 12061 net.cpp:270] This network produces output loss I0113 16:14:19.065475 12061 net.cpp:283] Network initialization done. I0113 16:14:19.065738 12061 solver.cpp:181] Creating test net (#0) specified by net file: /home/zfq/ero/ero_train_val.prototxt I0113 16:14:19.065779 12061 net.cpp:322] The NetState phase (1) differed from the phase (0) specified by a rule in layer data I0113 16:14:19.065958 12061 net.cpp:58] Initializing net from parameters: name: "eroNet" I0113 16:14:19.066334 12061 net.cpp:100] Creating Layer data I0113 16:14:19.066344 12061 net.cpp:408] data -> data I0113 16:14:19.066350 12061 net.cpp:408] data -> label I0113 16:14:19.066359 12061 data_transformer.cpp:25] Loading mean file from: /home/zfq/ero/ero_img_mean.binaryproto I0113 16:14:19.086824 12072 db_lmdb.cpp:35] Opened lmdb /home/zfq/ero/img_test_lmdb I0113 16:14:19.109524 12061 data_layer.cpp:41] output data size: 50,3,160,120 ... ... I0113 16:14:19.871476 12061 net.cpp:283] Network initialization done. I0113 16:14:19.871577 12061 solver.cpp:60] Solver scaffolding done. I0113 16:14:19.872050 12061 caffe.cpp:252] Starting Optimization I0113 16:14:19.872056 12061 solver.cpp:279] Solving eroNet I0113 16:14:19.872074 12061 solver.cpp:280] Learning Rate Policy: step I0113 16:14:19.873565 12061 solver.cpp:337] Iteration 0, Testing net (#0) I0113 16:14:21.313458 12061 solver.cpp:404] Test net output #0: accuracy = 0.5 I0113 16:14:21.313494 12061 solver.cpp:404] Test net output #1: loss = 0.704497 (* 1 = 0.704497 loss) I0113 16:14:21.493621 12061 solver.cpp:228] Iteration 0, loss = 0.801923 I0113 16:14:21.493643 12061 solver.cpp:244] Train net output #0: loss = 0.801923 (* 1 = 0.801923 loss) I0113 16:14:21.508219 12061 sgd_solver.cpp:106] Iteration 0, lr = 0.001 I0113 16:22:07.501768 12061 solver.cpp:228] Iteration 900, loss = 0.0746734 I0113 16:22:07.501907 12061 solver.cpp:244] Train net output #0: loss = 0.0746734 (* 1 = 0.0746734 loss) I0113 16:22:07.501930 12061 sgd_solver.cpp:106] Iteration 900, lr = 0.001 I0113 16:22:58.975893 12061 solver.cpp:337] Iteration 1000, Testing net (#0) I0113 16:23:00.661041 12061 solver.cpp:404] Test net output #0: accuracy = 0.962 I0113 16:23:00.661064 12061 solver.cpp:404] Test net output #1: loss = 0.0888481 (* 1 = 0.0888481 loss) I0113 16:23:00.822790 12061 solver.cpp:228] Iteration 1000, loss = 0.130788 I0113 16:23:00.822813 12061 solver.cpp:244] Train net output #0: loss = 0.130788 (* 1 = 0.130788 loss) I0113 16:23:00.822819 12061 sgd_solver.cpp:106] Iteration 1000, lr = 0.001
可以看到第0次测试的时候准确率为0.5,说明网络初始化正常,接下来训练1000次就达到96%的准确率了,可以看到即使减少了caffenet大概3/4的参数仍然足够复杂去应对这样一个简单的问题。然后我总共设了训练次数为50000(原来的caffenet solver可是450000次),就去吃饭了,又去健了会身,回来大概过了两小时,才到20000次,我就手动把它停掉了,模型已经够好了
I0113 19:44:03.330700 20738 solver.cpp:244] Train net output #0: loss = 5.3437e-05 (* 1 = 5.3437e-05 loss) I0113 19:44:03.330721 20738 sgd_solver.cpp:106] Iteration 21900, lr = 1e-05 I0113 19:44:54.060794 20738 solver.cpp:337] Iteration 22000, Testing net (#0) I0113 19:44:55.744976 20738 solver.cpp:404] Test net output #0: accuracy = 0.994 I0113 19:44:55.745004 20738 solver.cpp:404] Test net output #1: loss = 0.0317426 (* 1 = 0.0317426 loss) I0113 19:44:55.910691 20738 solver.cpp:228] Iteration 22000, loss = 0.000167461 I0113 19:44:55.910719 20738 solver.cpp:244] Train net output #0: loss = 0.000167488 (* 1 = 0.000167488 loss) I0113 19:44:55.910724 20738 sgd_solver.cpp:106] Iteration 22000, lr = 1e-05 ^CI0113 19:45:24.555495 20738 solver.cpp:454] Snapshotting to binary proto file /home/zfq/ero/ero_train_iter_22057.caffemodel I0113 19:46:25.391970 20738 sgd_solver.cpp:273] Snapshotting solver state to binary proto file /home/zfq/ero/ero_train_iter_22057.solverstate I0113 19:46:26.212227 20738 solver.cpp:301] Optimization stopped early. I0113 19:46:26.329540 20738 caffe.cpp:254] Optimization Done
测试网络
首先使用c++程序进行测试,修改softmax_loss_layer.cu,加上以下几行:
std::ofstream fpzfq("/home/zfq/ero/predict.txt");
//save predict probability
const Dtype* prob_data_cpu_data = prob_.cpu_data(); //获取cpu_data
int batchSize = prob_.count();
for (int i = 0; i < (batchSize/2); i++ )
{
fpzfq << *(prob_data_cpu_data + (i * 2 + 1)) << "\n";
}
重新编译完了,直接命令行caffe test -model /home/zfq/ero/ero_train_val.prototxt -weights \
/home/zfq/ero/ero_train_iter_20000.caffemodel -gpu 0 -iterations 40
输出:
I0113 20:32:07.204973 31047 caffe.cpp:285] Running for 40 iterations. I0113 20:32:07.274396 31047 caffe.cpp:308] Batch 0, accuracy = 1 I0113 20:32:07.274413 31047 caffe.cpp:308] Batch 0, loss = 9.63219e-07 I0113 20:32:07.313727 31047 caffe.cpp:308] Batch 1, accuracy = 1 I0113 20:32:07.313743 31047 caffe.cpp:308] Batch 1, loss = 0.00906426 I0113 20:32:07.352495 31047 caffe.cpp:308] Batch 2, accuracy = 0.98 I0113 20:32:07.352511 31047 caffe.cpp:308] Batch 2, loss = 0.118276 I0113 20:32:07.391337 31047 caffe.cpp:308] Batch 3, accuracy = 1 I0113 20:32:07.391353 31047 caffe.cpp:308] Batch 3, loss = 1.47344e-06 ... ... I0113 20:32:08.579504 31047 caffe.cpp:308] Batch 37, accuracy = 1 I0113 20:32:08.579519 31047 caffe.cpp:308] Batch 37, loss = 2.6629e-05 I0113 20:32:08.614357 31047 caffe.cpp:308] Batch 38, accuracy = 0.98 I0113 20:32:08.614373 31047 caffe.cpp:308] Batch 38, loss = 0.157286 I0113 20:32:08.648746 31047 caffe.cpp:308] Batch 39, accuracy = 1 I0113 20:32:08.648761 31047 caffe.cpp:308] Batch 39, loss = 6.51854e-05 I0113 20:32:08.648764 31047 caffe.cpp:313] Loss: 0.031393 I0113 20:32:08.648787 31047 caffe.cpp:325] accuracy = 0.9935 I0113 20:32:08.648795 31047 caffe.cpp:325] loss = 0.031393 (* 1 = 0.031393 loss)
以上只是正常caffe流程输出的准确率和loss而已,对于每个test图像的为1概率值(即nsfw概率值)存在了prdict.txt里:
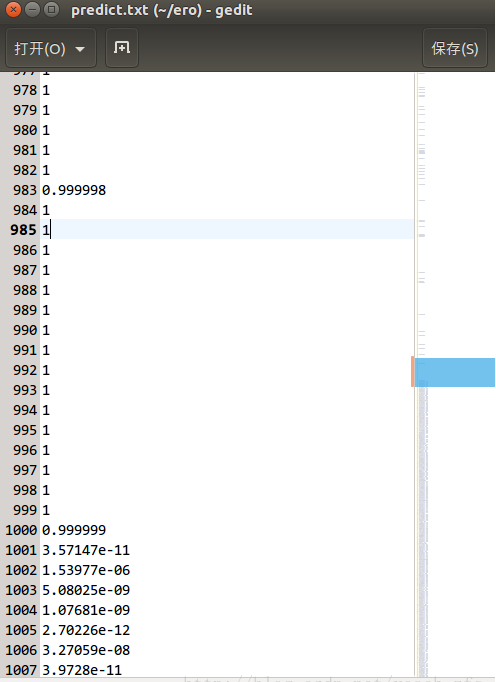
可以发现准确率真的是相当高,毕竟那么深的网络,那么多参数,就只训练了个二分类嘛
为了方便后面的单张图片进行测试,写了python版的测试命令,毕竟大多数情况下还是要测试单张图片,上面使用c++程序的test命令是针对准备好的lmdb格式的数据,参考caffe的python接口学习(6):用训练好的模型(caffemodel)来分类新的图片, caffe学习入门:pycaffe的使用, Caffe学习系列(15):计算图片数据的均值.
注意python所用的图像均值文件和c++里所用的图像均值文件不一样,所以用了上面最后一个链接提供的解决方法,感谢博主~
python程序:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 5 22:38:34 2017
@author: zfq
"""
import caffe
import os
import numpy as np
pythonPredict = open('/home/zfq/ero/python_predict.txt', 'w')
root = '/home/zfq/ero/ero_test/'
prototxt = '/home/zfq/ero/deploy.prototxt' #deploy文件
caffe_model = '/home/zfq/ero/ero_train_iter_20000.caffemodel' #训练好的 caffemodel
mean_file = '/home/zfq/ero/ero_mean.npy'
fileList = []
for i in range(1000):
fileName = root + str(9001+i) + '.jpg'
fileList.append(fileName)
for i in range(1000):
fileName = root + str(i+19001) + '.jpg'
fileList.append(fileName)
net = caffe.Net(prototxt, caffe_model, caffe.TEST) #加载model和network
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) #设定图片的shape格式
transformer.set_transpose('data', (2,0,1)) #改变维度的顺序
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0)) #交换通道,将图片由RGB变为BGR
def Test( img ):
im = caffe.io.load_image(img) #加载图片
net.blobs['data'].data[...] = transformer.preprocess('data',im) #执行上面设置的图片预处理操作,并将图片载入到blob中
#执行测试
out = net.forward()
prob= net.blobs['prob'].data[0].flatten() #取出最后一层(Softmax)属于某个类别的概率值,并打印
predict_label = prob[1]
print predict_label
pythonPredict.write(str(predict_label) + '\n')
for i in range(len(fileList)):
img= fileList[i]
Test(img)输出的值我也存在一个predict.txt里了,由于对于caffe的python接口还不是太熟悉,为了验证其正确性,我把c++程序和python程序输出的predict.txt做了个对比,实在懒得学numpy的相关命令了,我直接导入到matlab里了o(╯□╰)o。。相关命令:
cpre = load('/home/zfq/ero/predict.txt');
ppre = load('/home/zfq/ero/python_predict.txt');
groundTruth = load('/home/zfq/ero/ero_test_label.txt');
mean(round(cpre) == gt )
mean(round(cpre) == round(ppre))
diff = (round(cpre) == round(ppre))反正最后互相比较了一下,有差别,其中有三四个甚至完全预测相反了,不过总的准确率也都在99.3以上,应该影响不大。
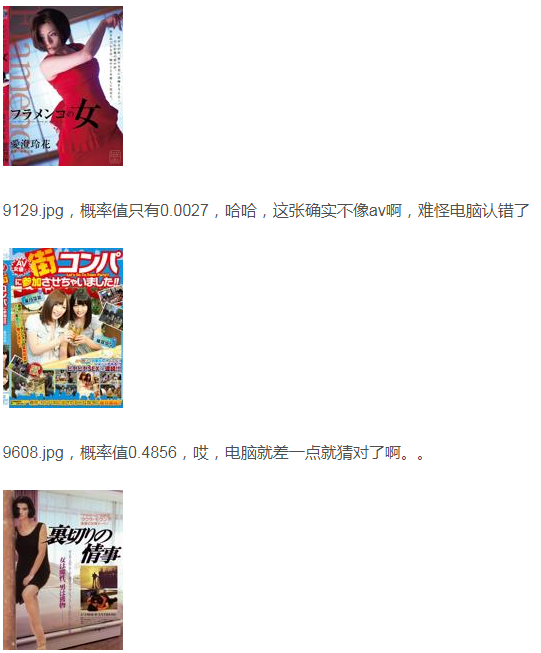
最后先来看看测试数据集里哪些测错了? 根据predict.txt我们可以很轻松地找到这几个预测错了

下面列出几张,二分类预测为1的概率值越接近1就越色情嘛。。:

好的,接下来我们直接百度图片“美女”来测试它的nsfw值?我们看预测为1的概率,越接近1越色情,越接近0越健康。。。:
大家自己去百度吧,我都不敢贴图了,好怕写了这么久被河蟹啊。。。
比如第一页的这个(╬ ̄皿 ̄)
我把它下载下来后先裁成合适的大小(这也是我目前遇到的最大的问题 ,下一步要解决这个,对caffe内部的crop和不同size的图像是怎么处理的还不太清楚。。)
直接python:img = '/home/zfq/ero/baiduImg/test_1.jpg';Test(img)得到的概率值为

哈哈,这个是1的概率这么高,百度真的是。。。
来测几张gakki当年的写真:


嗯。。。果然是有很多问题的。。由于训练数据过少,过极端,效果肯定不好,也可以说参数太多分类过少,网络过拟合了,即只对训练和测试数据集所在的高维空间做了极致的分类,而对它没见过的图片完全不知道该分到哪,泛化能力太差。。不过针对电影封面效果应该很不错,对于一般图片的话会存在很多问题。。
新人闲来无聊尝试而已,数据集很小易获得,caffemodel也好训练,我的GTX1060大概10分钟就可以达到95%的准确率,就没必要git了,前面也介绍了更好玩的雅虎的nsfw。
感谢开源社区,极大地促进了科技进步~现在感觉深度学习很多时候就是在拼数据量,等哪天爬到足够多的二次元图片并人肉整理后,我也会公开数据集的,欢迎小伙伴们共同参与,促进二次元的智能化>.<~~
(哈哈,不管做不做得到 先立个flag。。)
---------------------
作者:zhaofenqiang
来源:CSDN
原文:https://blog.csdn.net/roach_zfq/article/details/54426133
版权声明:本文为博主原创文章,转载请附上博文链接!



")
")
常用的6种方法")
 封装运动功能")
Qt Widgets Designer界面设计器和界面应用")
:有无数组?字符串方法,读写文件,序列化,配置文件,异常处理,循环和选择,模块与包,调试手段")


:基础知识")


:if的bool判断, 变量的作用域范围, 格式字符串, 弹窗, 列表推导式, 一个点歌小程序")