少有人走的路
少有人走的路目 录
摘 要
Abstract
1 绪论
2 CUDA技术概况
2.1 CUDA架构
2.2 CUDA的硬件模型
2.3 CUDA软件环境和编程模型
2.4 CUDA开发平台的搭建
2.4.1软件安装和环境配置
2.4.2创建工程
3 基于CUDA的图像旋转实现
3.1 实现图像旋转的方案选择
3.1.1适用于SPMD计算的图像变换算法
3.1.2 纹理技术
3.2 基于CUDA的数字图像几何变换方案
3.3 基于CUDA的数字图像几何变换的方案实现
3.3.1 CUDA初始化
3.3.2 纹理参数的拾取和坐标变换
3.3.3 数据传送至GPU并由GPU完成并行化核心过程
3.3.4 数据回传
3.4 实验结果和分析
4 结论与展望
参考文献
摘 要
CUDA 是GPU 通过并发执行多个线程以实现大规模快速并行计算能力的技术,它能使对GPU 编程变得更容易。介绍了CUDA 基本特性及主要编程模型,在此基础上,提出并实现了基于NVIDIA CUDA技术的图像快速几何变换。采用CUDA纹理技术,并把CUDA 技术的快速并行计算能力应用到数字图像几何变换中,解决了基于CPU 的传统图像几何变换运算效率低下的问题。实验结果证明使用CUDA 技术,随着处理图像尺寸的增加,对数字图像几何变换处理效率最高能够提高到近100 倍。
关键字:CUDA; 并行化; 数字图像; GPU 编程;纹理;
Abstract
CUDA is a type of technology that performs general purposes fast and parallel computation by running tens of thousands of threads concurrently. It makes users develop general GPU programs easily. This paper analyzes the distinct features of CUDA and summarizes the general program mode of CUDA. Furthermore,it proposes and implements an image geometric transform process by the CUDA. By using the texture technology, and by applying the rapid parallel computing ability of CUDA to transform the geometric image, solve the problem of the inefficient image transform based on CPU. The experimental results show that, as the image size increase, application of CUDA on image geometric transform can reach to more than 100x.
Keywords: CUDA; parallelization; digital image; GPU programming;Texture;
1 绪论
l 研究背景
在某些如车牌识别系统等对实时性要求较高的有大量图像处理工作的系统开发中,对从摄像设备中获取的原始图像的预处理所耗费的时间占了很大比重,如何最大限度地减少图像预处理所耗费的时间成为提高这类实时系统性能的关键。图像几何变换是预处理的一个重要方面,并行化是解决这类问题的一个思路。近年来计算机图形处理器(Graphic ProcessingUnit,GPU)高速发展,极大地提高了计算机图形处理的速度和图形质量,同时也具有高度的可程序化能力,这使得通过GPU 实现数字图像几何变换并行化成为可能。由于显示芯片通常具有相当高的内存带宽,以及大量的执行单元,绘制流水线的高速度和并行性为图形处理以外的通用计算提供了良好的运行平台,这使得基于GPU 的通用计算成为近几年人们关注的一个研究热点。
并行计算已成为突破摩尔定理局限性的重要研究方向,而GPU强大的并行计算能力也因此吸引了全球广泛的研究兴趣。然后,在时间通用并行计算时,GPU计算模式存在着一些限制。首先,GPU的设计初衷是为了加速程序中的图形绘制运算,因此开发人员需要通过OpenGL或者API来访问GPU,这不仅要求开发人员掌握一定的图形编程知识,而且要想方设法将通用计算问题转为图形计算问题。其次,GPU与多核CPU在计算构架上有着很大不同,GPU更注重于数据并行计算,即在不同的数据上并行执行相同的计算,而对并行计算中的互斥性,同步性以及原子性等方面支持不足,这些因素都限制了GPU在通用并行计算中的引用范围。CUDA架构的出现解决了上述问题。
CUDA™ 是NVIDIA® 公司的并行计算架构。该架构通过利用 GPU 的处理能力,可大幅提升计算性能。
目前为止基于 CUDA的GPU销量已达数以百万计,软件开发商、科学家以及研究人员正在各个领域中运用CUDA,其中包括图像与视频处理、计算生物学和化学、流体力学模拟、CT图像再现、地震分析以及光线追踪等等。
计算正在从CPU「中央处理」向CPU与GPU「协同处理」的方向发展。为了实现这一新型计算模式,NVIDIA发明了CUDA 并行计算架构。该架构现在正运用于 Tesla® 、Quadro® 以及 GeForce® GPU 上。对应用程序开发商来说,CUDA 架构拥有庞大的用户群。
在科学研究领域,CUDA受到狂热追捧。例如,CUDA能够加快AMBER 这款分子动力学模拟程序的速度。全球有6万余名学术界和制药公司的科研人员使用该程序来加速新药开发。在金融市场,Numerix和CompatibL 已宣布在一款对手风险应用程序中支持 CUDA,而且因此实现了18倍速度提升。
在 GPU 计算领域中,Tesla GPU的大幅增长说明了CUDA 正被人们广泛采用。 目前,全球「财富」五百强企业已经安装了700多个GPU集群,从能源领域中的斯伦贝谢和雪佛龙到银行业中的法国巴黎银行,这些企业的范围十分广泛。
l CUDA的优势
CUDA(Computer Unified DeviceArchitecture)是NVIDIA 的GPU 编程模型,它的编程模式是单程序多重数据(Single Program MultipleData,SPMD) ,即多个并发的线程执行单一的程序来处理多重数据[1]。本文提出的基于CUDA 的图像并行几何变换并不仅是将传统的基于CPU 的图像几何变换算法简单机械移植到具有并行计算能力的GPU 中。通过对传统的数字图像几何变换的分析,尽量减少原算法中的冗余乘法运算,然后利用CUDA 技术并发执行的优点,并发执行多个线程对图像的像素点进行同步几何变换,因此大幅提高了变换效率。
基于CUDA计算的优点:
GPU通常具有更大的内存带宽。
GPU具有更多的执行单元。
GPU较同等级的CPU具有价格优势。
在CUDA上实现的应用具有一个共同的特征,就是个CUDA线程所处理的数据相互之间独立性很高,线程间通信很少或者没有。每个线程所处理的数据被称为单位数据,是一段内存空间,可以是1bit,或者1Byte,或者一个数据或者字符串。我们将这种单位数据间能够被并行处理的性质称为数据并行性。处理的数据具有数据并行性的应用称为数据并行应用。
l 研究内容和目的
本文介绍了CUDA基本特性以及主要编程模型,在此基础上,提出并实现了基于NVIDIA CUDA技术的数字图像快速几何变换,采用CUDA的纹理技术进行数字图像的几何变换,代替原变换中大量乘法运算,并把CUDA技术的快速并行计算能力应用到数字图像几何变换中,解决了基于CPU的传统图像几何变换运算效率低下的问题。
l CUDA的应用领域
由于GPU的特点是处理密集型数据和并行数据计算,因此CUDA非常适合需要大规模并行计算的领域。目前CUDA平台支持C语言和FORTRAN的开发,CUDA平台以后预计将进一步支持Python、C++、Java等语言。
CUDA技术已经成功应用在下列涉及大规模密集型数据计算的领域:金融、电信、证券分析;能源勘探开发;搜索引擎的应用;数据库和数据挖掘;医药工程等。在未来,随着CUDA平台的继续发展,CUDA技术将应用于更多的领域。
1. CUDA应用举例:实时的裸眼立体医疗成像系统
裸眼立体成像技术是成像技术中一个很有趣的技术应用,裸眼立体成像技术不需要使用者使用特殊的眼镜就能让使用者看到三维的立体图像。裸眼立体成像技术可以和其它领域的技术结合,实现其它领域内的重要应用。特别是这种技术在娱乐方面有着巨大的应用潜力。这种技术涉及到特别巨大的计算量,东京大学的Takeyoshi教授认为NVDIA的CUDA平台可成功实现裸眼立体成像技术应用于医疗成像。并且东京大学的研究小组在2000年时已经成功开发出一种应用裸眼立体成像的医疗成像系统,该系统使用CT和MRI技术实时扫描得到的活体截面图作为被体纹理,通过进一步体绘制实现为裸眼立体成像的三维图像。系统涉及的计算量极其巨大,并且需要在极短的时间下高精度地实现这样的计算。
2. CUDA应用举例:VMD/NAMD分子动力学
NAMD是一个重要的医学应用程序类别。分子动力学是一种用于生物学研究的基本工具。之前,伊力诺依州立大学的研究人员在它们的网站上发布了一款GPU加速版的视觉分子动力学工具,而最近,又发布了一款纳米级分子动力学工具。该工具可以从他们的网站上免费下载。NAMD MD是将并行计算应用于生物学中的基本工具的一个典型案例.
3. CUDA应用举例:视频转换加速
利用CUDA实现GPU计算来为应用程序提速,Badaboom就是很好的一例,这是一款CUDA开发的视频转换软件,可以把mpeg2的视频转换为ipod或者iphone这样的所使用的H.264视频格式。选取一段码率较高的MPEG2视频,可以看到GTX 280的处理速度达到了80FPS左右,如果码率较小,还可以达到100FPS以上甚至更高。328MB的MPEG2视频转换成17.4MB的iPhone可用的MP4视频(640*365),只用了37s。而同样平台下用CPU进行计算,得到的结果是耗时107s,几乎是用GTX 280转换耗时的三倍。
4. CUDA应用举例:Folding@home
Folding@home是美国史丹佛大学推动的分散式运算计划,目的在于使用联网式的计算方式和大量的分布式计算能力来模拟蛋白质折叠的过程,并指引对由折叠引起的疾病的一系列研究。NVIDIA的CUDA显卡也加入了Folding@home计划,目前全球有8000万块CUDA显卡,平均拥有100GFLOPS的浮点运算能力,如果这其中有0.1%参与Folding@Home,就能够为该计划带来7PFLOPS的运算能力。
2 CUDA技术概况
2.1 CUDA架构
GPU在速度上之所以会有如此巨大的变革主要是因为它本身的设计原理。GPU使用更多的晶体管来用于数据处理,其数量远大于数据缓存和流控制。GPU特别适合处理那些并行数据计算一即同一程序并行地在许多数据元素上执行。这样一来,它对于流控制的要求就不是很高,而且运算将代替大数据缓存来隐藏内存存取延迟。数据元素通过数据并行处理机制映射到每个并行处理线程上。许多处理大数据集的应用程序,如数组,可以通过使用一个数据并行处理模型来加速计算。在3D渲染中,像素和顶点集可以映射到并行线程。同样,图形图像处理程序,如视频编解码,图像缩放和模式识别等,可以映射块和像素到并行处理线程上。事实上,除了图像渲染和处理领域,其他领域的许多计算也可以通过数据并行处理得以加速,例如信号处理,物理仿真,金融工程以及生物信息学。
然而,直到现在,GPU要实现这样的应用还是存在许多困难的:
1)GPU只能通过一个图形的API来编程,这不仅加重了学习负担更造
2)由于DRAM内存带宽,一些程序会遇到瓶颈。
3)无法在DRAM上进行通用写操作。
CUDA(Compute Unified Device Architecture,计算机统一设备架构)是一种新的处理和管理GPU计算的硬件和软件架构,它将GPU视作一个数据并行计算没备,并且无需把这些计算映射到图形API。GeForce 8,Tesla解决方案和一些Quadro解决方案已经提供了CUDA。操作系统的多任务机制可以同时管理CUDA访问GPU和图形程序的运行时刻。
CUDA在软件方面组成有:一个硬件驱动,一个应用程序接口和运行时,两个通用算术库一CUFFT和CUBI。AS。CUDA改进了DRAM的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA提供了片上共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少DRAM的数据传送,更少的依赖DRAM的内存带宽。
在之前的图形处理架构中,计算资源划分为顶点着色器和像素着色器,而CUDA架构则不同,它包含了一个统一的着色器流水线,使得执行通用计算的程序能够对芯片上的每个数学逻辑单元(ALU)进行排列。由于NVIDIA希望使新的图形处理器能适用于通用计算,因此在实现这些ALU时都确保它们能够满足IEEE单精度浮点数学运算的需求。此外,GPU上的执行单元不仅能任意地读/写内存,同事还能访问由软件管理的缓存,也称为共享内存。CUDA架构的所有这些功能都是为了使GPU不仅能执行传统的图形计算,还能高效的执行通用计算。
NVIDIA并不局限于通过几成CUDA架构的硬件来为消费者同时提供计算功能和图形功能。机关NVIDIA的芯片中增加了许多功能来加速计算,但任然只能通过OpenGL或者DirectX来访问这些功能。这不仅要求用户任然要将他们的计算任务伪装为图形问题,而且还需要使用面向图形的着色语言来编写计算代码。
为了尽可能地吸引更多的开发人员,NVIDIA采取了工业标准的C语言,并且增加了一小部分关键字来支持CUDA架构的特殊功能,在发布了了GeForce 8800 GTX之后的几个月,NVIDIA公布了一款编译器来编译CUDA C语言,这样,CUDA C就称为了第一款专门有GPU公司设计的编程语言,用于在GPU上编写通用计算。
除了专门设计一种语言来为GPU编写代码以后,NVIDIA还提供了专门的硬件驱动程序来发挥CUDA架构的大规模计算功能。现在,用户不需要了解OpenGL或者DirectX图形编程结构,也不需要将通用计算问题伪装为图形计算问题。
2.2 CUDA的硬件模型
CUDA的硬件结构模型如图2.1,包括多个SIMD多处理器,每个多处理器具有4种类型的芯片内存储器:本地寄存器,并行数据告诉缓存,只读常量高速缓存,只读纹理高速缓存,后三种存储器可以通过主机读或者写,并永久存在于响应应用程序的内核启动中。
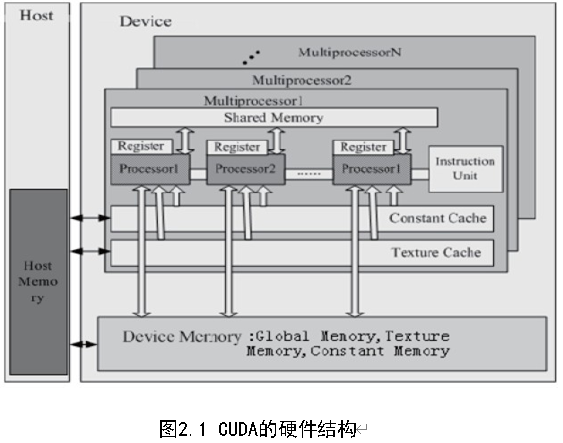
这个模型有以下几个特点:
1) 全局读写存储器:GPU 能够从任意位置和存储器中获取数据,也可以将数据写入任何存储器中,这几乎和CPU 一样具有灵活性。
2) 线程共享存储器:它可以使得在同一个处理器中的线程快速获取数据,避免从全局变量存储器中存取。共享存储器的访问速度几乎寄存器一样快,从这里获取数据仅仅需要4 个时钟周期,然而全局变量存储器的访问花费为400-600 个时钟周期。
3) 线程同步:处在同一个线程组的线程组能够进行同步操作,因此他们可以通迅和协作以解决一些复杂的问题。
2.3 CUDA软件环境和编程模型
CUDA的软件体系由CUDA库函数、运行时API、驱动组成,如图2.2所示。在CUDA的软件层面,NVIDIA C编译器是其中的核心。CUDA程序是GPU和CPU的混合代码, 它首先由NVIDIA C编译器进行编译。经过编译后,GPU和CPU的代码将被分离,GPU代码被编译成GPU计算的机器码,而CPU的C代码输出由标准的C编译器进行编译。因此一个完整的CUDA软件开发环境还需要有一个面向CPU的C编译器。CUDA可以支持多种运行在Windows XP和Linux操作系统下的C开发系统诸如Microsof Visual C++等。右图是NVIDIAC编译器结构。其中,EDG将CPU和GPU的代码分离;Open64生成GPU PTX(ParallelThread eXecution) 汇编码。CUDA运行需要CUDA runtime driver的支持,而Profiler则可以提供GPU和CPU kernel调用和内存拷贝的时序分析,从而对性能进行评估并且发现潜在的性能上的问题。
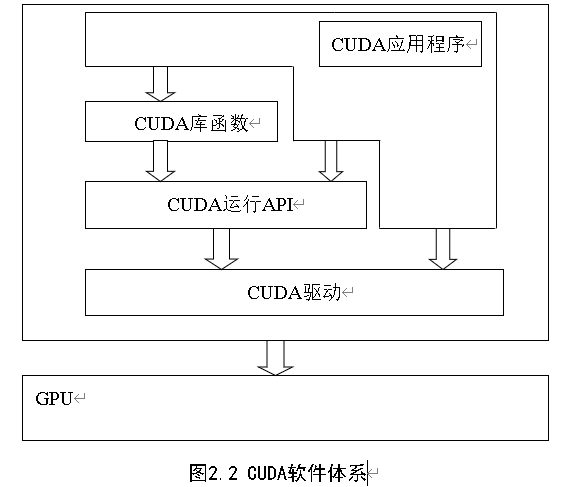
除了编译器外,NVIDIA提供了一些非常实用的函数库。目前有两个数字计算库包含在已经发布的软件包里面,分别是CUDA FFT和CUDA BLAS子程序库。CUDA FFT是快速傅里叶变换的子程序库,快色傅里叶变换时信号处理之类应用的基本算法,BLAS是基本线性代数的子程序库。CUDA FFT和BLAS都是针对GPU高度优化的高性能数学函数库,在CUDA程序中可以方便调用,节省大量的代码编写时间。
CUDA程序构架分为两部分:Host和Device。一般而言,Host指的是CPU,Device指的是GPU。在CUDA程序构架中,主程序还是由CPU来执行,而当遇到数据并行处理的部分,CUDA就会将程序编译成GPU能执行的程序,并传送到GPU。而这个程序在CUDA里叫做内核。CPU主要负责要进行逻辑性强的事务处理和串行运算,GPU则专注于执行高度线程化的并行处理任务。CPU、GPU各自拥有相互独立的存储器地址空间:主机端的内存和设备端的显存。CUDA对内存操作与一般的C程序基本相同,但增加了一种可以被并行执行的步骤。运行在GPU上的CUDA并行计算函数称为kernel(内核函数)。一个kernel函数并不是一个完整的程序,而是整个CUDA程序中的一个可以被并行执行的步骤。CPU串行代码完成的工作包括在kernel启动前进行数据准备和设备初始化的工作,以及在kernel之间进行一些串行计算。理想情况是,CPU串行代码的作用应该只是清理上一个内核函数,并启动下一个内核函数。这样,就可以在设备上完成尽可能多的工作,减少主机与设备之间的数据传输。
在实际运行时,CUDA会产生许多在GPU上执行的线程,每一个线程都会去执行内核这个程序,虽然程序是同一份,但是因为索引不同,而取得不同的数据来进行计算。
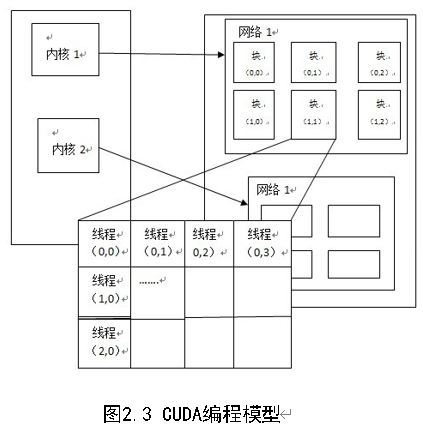
在GPU中要执行的线程,根据最有效的数据共享来创建块(Block),其类型有一维、二维或三维。在同一个块里的线程,使用同一个共享内存。另外,块的大小是有限制的,所以不能把所有的线程都塞到同一个块里(一般GPGPU程序线程数目是很多的);这时,可以用同样维度和大小的块(需同一个内核),来组成一个网格(Grid)做批处理(在同一个网格里的块,GPU只需编泽一次)。具体框架如图2.2所示。
CUDA对C语言进行了一些扩展,允许定义称为内核(kernel)的C函数。调用内核函数时,N个CUDA线程将内核函数并行执行N次。定义好使用__global__限定符声明内核函数,使用<<<…>>>语法设定调用的线程数。
我们看下面的CUDA程序例子:内核函数的对应执行线程都内置一个的线程ID,所有的线程ID不会相同。我们可以使用内置的threadIdx变量进行访问。程序代码实现把大小为N的向量A和B相加,结果存在向量C。执行核函数VecAdd()的每一个线程都处理一次相加运算。
__global__void VecAdd(int*A,int*B,int*C)
{
int i=threadIdx.x;
C[i]=A[i]+B[i];
}
int main()
{VecAdd<<<1,N>>>(A,B,C);
}
l 线程层次结构
可以使用多维的索引对线程进行标识,组成多维的线程块(thread block),核函数内置的threadIdx为一个有3分量的向量。如下面的CUDA代码示例,大小为NxN矩阵A和B相加,结果存在矩阵C中。
__global__void MatAdd(int A[N][N],int B[N][N],int C[N][N])
{
int i=threadIdx.x;
int j=threadIdx.y;
C[i][j]=A[i][j]+B[i][j];
}
int main()
{
dim3 dimBlock(N,N);
MatAdd<<<1,dimBlock>>>(A,B,C);
}
同个块内线程可同步,使用共享存储器(shared memory)实现共享数据。通过调用内建函数__syncthreads()实现在核函数中同步。同一个块的所有的线程须都在同一处理器内核。一个核函数可由多个相同规格的线程块执行,组成一个多维度的线程块网格Grid,Grid的维度由<<<>>>语法设置。网格中的块可由多维索引标识,内核函数可通过blockIdx中访问,可以通过blockDim访问线程块的维度。我们可以用多维的网格实现上面的程序。
__global__void matAdd(int A[N][N],int B[N][N],int C[N][N])
{int i=blockIdx.x*blockDim.x+threadIdx.x;
int j=blockIdx.y*blockDim.y+threadIdx.y;
if(i<N&&j<N)
C[i][j]=A[i][j]+B[i][j];
}
int main()
{dim3 dimBlock(16,16);
dim3 dimGrid((N+dimBlock.x–1)/dimBlock.x,
(N+dimBlock.y–1)/dimBlock.y);
matAdd<<<dimGrid,dimBlock>>>(A,B,C)}
l 存储器层次结构
CUDA有一个多层次的存储器结构。一个线程有一个局部存储器(local memory)。每一个线程块有一个块内所有线程共有的共享存储器(shared memory)。所有线程共有一个全局存储器(global memory)和两个只读存储器:常量存储器(constant memory)和纹理存储器(texture memory)。多层次的存储器结构适于不同的用途。
l 宿主和设备
CUDA线程在独立设备(device)上执行,C程序其它部分在CPU(宿主)上执行。串行代码在宿主上执行,而并行代码在设备上执行。
通过CUDA编程时,将GPU看作可以并行执行非常多个线程的计算设备(compute device)。它作为主CPU的协处理器或者主机(host)来运作:换句话说,在主机上运行的应用程序中数据并行的、计算密集的部分卸载到此设备上。
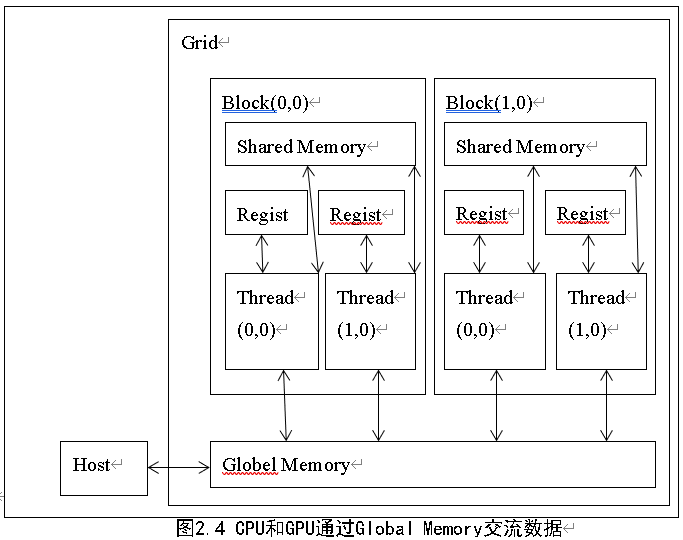
经过了CUDA对线程、线程块的定义和管理,在支持CUDA的GPU内部实际上已经成为了一个迷你网格计算系统。在内存访问方面,整个GPU可以支配的存储空间被分成了寄存器(Register)、全局内存(External DRAM)、共享内存(Parallel Data Cache)三大部分。其中寄存器和共享内存集成在GPU内部,拥有极高的速度,但容量很小。共享内存可以被同个线程块内的线程所共享,而全局内存则是我们熟知的显存,它在GPU外部,容量很大但速度较慢。经过多个级别的内存访问结构设计,CUDA已经可以提供让人满意的内存访问机制,而不是像传统GPGPU那样需要开发者自行定义。图2.4为CPU与GPU通过Globle Memory交换数据。
2.4 CUDA开发平台的搭建
2.4.1软件安装和环境配置
本次开发是在window7 32位上的,硬件条件为NVIDIA GeForce GT 550M显卡下,使用到的软件为Microsoft Visual Studio 2010和CUDA5.0。
1)Visual Studio 2010及Visual Assist X安装
先安装Visual Studio 2010 后再安装助手Visual Assist X。这里Visual Assist X 对于使用CUDA 作并行计算不是必须的,但为了使程序编写更为方便,这里 推荐安装。
2)安装cuda5.0
CUDA Toolkit的默认安装目录为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0
CUDA SDK的默认安装目录为:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v5.0
3)配置环境变量
安装完成Toolkit 和SDK 后,已自动配置好系统环境变量。保险起见,手动配置环境变量。在系统环境变量中新建如下项:
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v5.0\common
CUDA_PATH = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0
CUDA_LIB_PATH = %CUDA_PATH%\lib\Win32
CUDA_BIN_PATH = %CUDA_PATH%\bin
CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\Win32
CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\Win32
2.4.2创建工程
在Visual Studio 2010 菜单选择“file|new|project(文件|新建|工程)”,在打开的新建项目窗口的“已安装的模板”一栏中选择“NVIDIA|CUDA”,类型选择为“CUDA 5.0 Runtime”,见下图3.2。
在“名称”中输入工程名后,点击确定。可对系统提供的kernel.cu 示例进行编译运行,运行结果如下图3.3。
图2.6 kernel.cu程序运行图
工程建立完毕,接下来,我们需要添加.cu文件来编写代码,右击项目名称,选择“添加-新建项”,如图2.7所示:
选择CUDA C/C++ File,输入项名称,点击提提那家,.cu文件添加完毕,我们可以在文件中添加代码,代码添加完毕之后,点“CTRL+F5”编译。
3 基于CUDA的图像旋转实现
3.1 实现图像旋转的方案选择
3.1.1适用于SPMD计算的图像变换算法
图像几何变换主要包括图像的平移,缩放,旋转及扭曲等。平移及缩放变换处理较为简单,只需要做加法处理即能得到最终结果,因此在变换算法上没有大的提升空间。图像的几何变换可以用一个线性方程组来描述:

图像的几何变换过程实质就是一个确定线性方程组系数值的过程。由于图像的像素点的位置是离散的,经过式(1)变换以后新的位置为P'(x ', y ')不一定正好落在一个像素上,即所谓的空穴现象[7]。采用逆向变换的方法可以解决这一问题。若变换过程P 采用直接求式(1)逆变换方法处理新图像的每一个像素点,每个点将会进行4 次乘法运算,那么对于变换之后的大小为M *N 的图像,将会产生4*M *N 次乘法运算。考虑采用位置增量来代替大量乘法运算,以进一步提高变换效率。将一大小为M *N 图像任意点(x, y)以点0 0 (x , y )为中心旋转θ ,变换后的位置为:
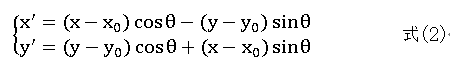
为了避免出现提到的所谓空穴点,采用逆变换方式,因此将式(2)做逆变换得:
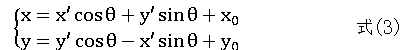
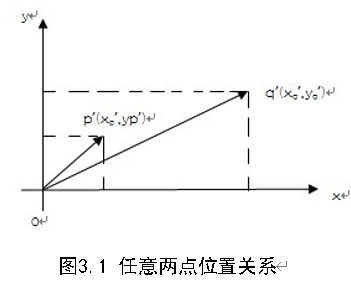
如图3.1所示,设p '和q ‘分别表示变换后新图像中两点,其位置关系可用式(4)表示

将式(4)带入式(3),最终得到:
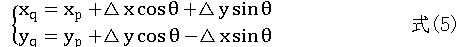
设 p '和q '为同一行的两个像素点,则Δy = 0。因此在同一行中任意一点q '与行首点 0 X 在原图像的位置偏移量[8],Δx ,Δy为:
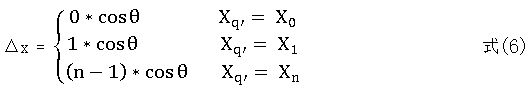
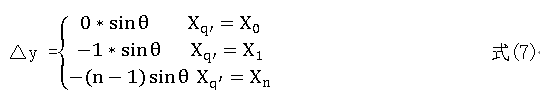
由上式可以看出, 任意同一行中点q' , 1, 2,..., n q n = N 的 X 方向及Y 方向上的位置偏移量与其对应的坐标具有线性增量关系。同一列像素点位置偏移关系类似。这样,只要计算旋转图像中原点在原图中的位置,其余像素点均可通过上式求出其位置偏移量,进而计算出在原图像中的位置。由此,对于变换之后的大小为的M *N 图像,只需要计算原点位置时进行4 次乘法操作,其余点均可以加法操作代替乘法操作。
由采用位置偏移量的方法将图像变换需要4*M *N 次乘法运算变成只需要2*M *N 次加法运算,在效率上很大提高。至此,M *N 次加法运算成为图像变换算法中最耗时的部分。注意到每个像素点在变换过程中都是执行相同的加法操作指令,且操作的数据具有线性关系,非常符合并行化的特点,可以进行并行运算。设X 为输入图像,Y 为输出图像,P为图像变换过程,|表示并行执行,则图像变换并行化可以表示为:
Y = P(X)=P1(X)|P2(X)|…Pn(X)
3.1.2 纹理技术
(1) 纹理属性
纹理可以在线性内存或是CUDA数组(纹理内存)的任何区域。所以纹理拾取也就对存在与线性内存或CUDA数组中的纹理读取数据。
共用运行组件(既可以运行在host又可以运行在设备)中给出了纹理类型texture。纹理拾取的第一个参数就是纹理参考,纹理参考定义要拾取哪部分纹理内存,它必须通过宿主运行时(只运行在宿主上)函数绑定到一些内存区域(称为纹理(texture)),然后才能供内核使用。下面就来看看纹理参考的不可变属性和可变属性。
l 不可变属性
纹理参考的声明是texture texRef;Type、Dim和ReadMode都是不可变属性。其中:
Type指定拾取纹理时返回的数据类型;Type限制为基本的整数和浮点数类型,以及1-、2-和4-分量的向量类型之一。
Dim指定纹理参考的维度,等于1、2或3;Dim是可选参数,缺省值为1;
ReadMode等于cudaReadModeNormalizedFloat或cudaReadModeElementType。如果;ReadMode为cudaReadModeNormalizedFloat,且Type为16-位或8-位整数类型,则其值实际返回值为浮点数类型,即根据原整数类型的全范围进行归一化处理,结果被映射到 [0.0, 1.0]区间(对于无符号整数)或[-1.0, 1.0]为区间(对于有符号整数);例如,值0xff的无符号8-位纹理元素返回值为1;如果ReadMode为cudaReadModeElementType,则不执行任何转换;ReadMode是可选参数,默认为cudaReadModeElementType.
l 可变属性
纹理参考的可变属性包括寻址模式、纹理过滤和纹理坐标是否归一化。这些属性都是执行宿主运行时改变的,如cudaBindTextureToArray()执行时在硬件纹理单元(texture units)时。其中:
addressMode,即如何处理超出范围的纹理坐标。寻址模式是大小为2的数组,数组的第一个和第二个元素分别指定第一个第二个纹理坐标的寻址模式:当寻址模式等于cudaAddressModeClamp时,超出范围的纹理坐标将使用clamp寻址:非归一化纹理坐标的情况下,小于0的值设置为0,大于等于N的值设置为N-1;归一化纹理坐标的情况下,小于0.0或大于1.0的值设置到区间[0.0,1.0)中。当寻址模式是cudaAddressModeWarp时,超出范围的纹理坐标使用warp模式:warp寻址仅使用纹理坐标的小数部分:如1.25当作0.25处理,-1.25当作0.75处理。默认情况下是cudaAddressModeClamp。cudaAddressModeWarp只支持归一化的纹理坐标。
filterMode,过滤模式即当拾取纹理时,如何基于输入纹理坐标来计算返回的值。filterMode等于cudaFilterModePoint或cudaFilterModeLinear;如果它为cudaFilterModePoint,则返回值是纹理坐标最接近输入纹理坐标的纹理元素;如果它为cudaFilterModeLinear,则返回值是纹理坐标最接近输入纹理坐标的2个(对于1D纹理)、4个(对于1个2D纹理)或8给(对于3D纹理)的纹理元素的线性插值。cudaFilterModeLinear只对返回值是浮点类型有效。
normalize,指定纹理坐标是否是归一化的;如果其值非0,则纹理中的所有元素都使用区间[0,1],而非区间[0,width-1]、[0,height-1]或[0,depth-1]中的纹理坐标来寻址,其中width、height和depth是纹理大小。
在线性内存中分配的纹理:
1) 维度只能等于1;
2)不支持纹理过滤;
3)只能使用非归一化的整数纹理坐标寻址;
4)寻址模式单一:越界的纹理访问将返回0值。
(2) 纹理拾取函数
纹理拾取函数是设备运行时函数。纹理存储的区间不同,拾取的方式也不同。从线性内存中拾取,使用的函数是tex1Dfetch()的函数簇。如:
template<class Type>
Type tex1Dfetch(
texture<Type, 1, cudaReadModeElementType> texRef, int x);
float tex1Dfetch(
texture<unsigned char, 1, cudaReadModeNormalizedFloat> texRef,
int x);
这些函数用纹理坐标x拾取绑定到纹理参考texRef 的线性内存的区域。不支持纹理过滤和寻址模式。对于整数型,这些函数将会将整数型转化为单精度浮点型。除了这些函数,还支持2-和4-分量向量的拾取。如:
float4 tex1Dfetch(
texture<uchar4, 1, cudaReadModeNormalizedFloat> texRef,
int x);
用纹理坐标x拾取绑定到纹理参考的线性内存的区域。从CUDA数组中拾取,是用函数tex1D(),tex2D(),tex3D():
template<class Type, enum cudaTextureReadMode readMode>
Type tex1D(texture<Type, 1, readMode> texRef,float x);
template<class Type, enum cudaTextureReadMode readMode>
Type tex2D(texture<Type, 2, readMode> texRef,float x, float y);
template<class Type, enum cudaTextureReadMode readMode>
Typetex3D(texture<Type, 3, readMode> texRef,float x, float y, float z);
这些函数用用纹理坐标x,y,z拾取绑定到纹理参考 texRef 的CUDA数组。纹理参考的可变和不可变属性决定了如何理解坐标,在纹理拾取和返回值将做怎样的处理。
(3) 拾取纹理内存与读取全局或常量内存相比的优点
1) 有高速缓存,如果CUDA数组中的纹理在片上的高速缓存中,则可以潜在的获得较高带宽
2) 不受访问模式的约束。全局或常量内存读取必须遵循相应访存模式才能获得好的性能。如全局内存在单个指令中将32-位、64-位或128-位从全局内存读取到寄存器,单个指令读取的位数要尽量多;另外每个半warp中同时访问全局内存地址的每个线程应该进行排列,以便内存访问可以合并到单个邻近的、对齐的内存访问中。
3) 寻址计算的延迟隐藏的更好,有时候会改善应用程序执行随机访问数据的性能。
4) 打包的数据可以在单个操作中广播到多个独立变量中
5) 8-位和16-位整数输入数据可以有选择地转化为[0.0,1.0]或[-1.0,1.0]区间内的32位浮点值\
6) 如果访问的是CUDA数组还有其他的功能,过滤、归一化纹理坐标、寻址模式
3.2 基于CUDA的数字图像几何变换方案
实现基于CUDA的数字图像几何变换的实现流程图如图3.2所示。
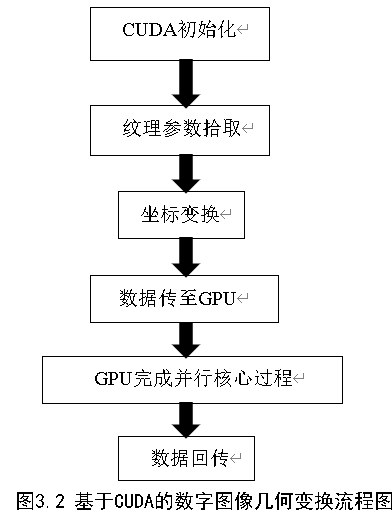
由上述流程图,我们可以看出,本次实现基于CUDA的数字图像几何变换主要分为六个部分:CUDA初始化,纹理参数拾取,坐标变换,数据传送至GPU,由GPU完成并行化核心过程,数据回传。
3.3 基于CUDA的数字图像几何变换的方案实现
3.3.1 CUDA初始化
首先,初始化CUDA,代码如附录1,结果如图4.2
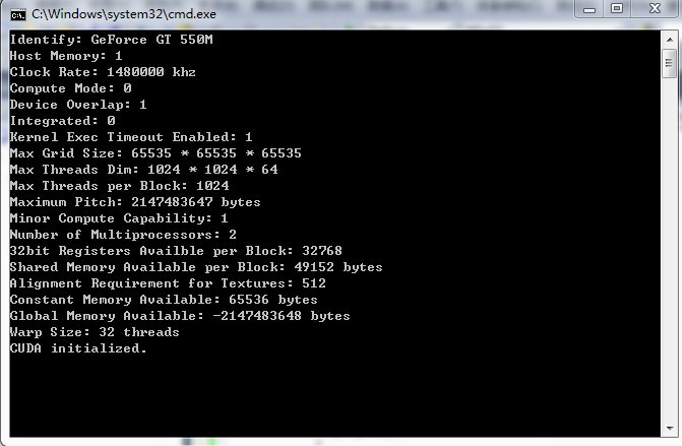
图3.3 初始化CUDA
3.3.2 纹理参数的拾取和坐标变换
通过纹理拾取函数,进行纹理参数的拾取,并对图片进行纹理坐标的计算和归一化纹理左边的变换。
// Constants
const float angle = 0.5f; // angle to rotate image by (in radians)
// Texture reference for 2D float texture
texture<float, 2, cudaReadModeElementType> tex;
// Auto-Verification Code
bool testResult = true;
//! Transform an image using texture lookups
//! @param outputData output data in global memory
__global__ void transformKernel(float *outputData,
int width,
int height,
float theta)
{
// calculate normalized texture coordinates
unsigned int x = blockIdx.x*blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y*blockDim.y + threadIdx.y;
float u = x / (float) width;
float v = y / (float) height;
// transform coordinates
u -= 0.5f;
v -= 0.5f;
float tu = u*cosf(theta) - v*sinf(theta) + 0.5f;
float tv = v*cosf(theta) + u*sinf(theta) + 0.5f;
3.3.3 数据传送至GPU并由GPU完成并行化核心过程
本过程有CPU读取参考图像,并为结果分配内存,配置阵列和复制图像数据,设置纹理参数,绑定数组纹理,由GPU完成并行化核心程序。
3.3.4 数据回传
GPU运行完毕,从主机侧为结果分配存储器,从设备复制结果到主机,把结果写进文件。
// Allocate mem for the result on host side
//在主机侧结果分配存储器
float *hOutputData = (float *) malloc(size);
// copy result from device to host
//从设备复制结果到主机
checkCudaErrors(cudaMemcpy(hOutputData,
dData,
size,
cudaMemcpyDeviceToHost));
// Write result to file
//把结果写进文件
char outputFilename[1024];
strcpy(outputFilename, imagePath);
strcpy(outputFilename + strlen(imagePath) - 4, "_out.pgm");
sdkSavePGM(outputFilename, hOutputData, width, height);
printf("Wrote '%s'\n", outputFilename);
// Write regression file if necessary
if (checkCmdLineFlag(argc, (const char **) argv, "regression"))
{
// Write file for regression test
sdkWriteFile<float>("./data/regression.dat",
hOutputData,
width*height,
0.0f,
false);
}
else
{
// We need to reload the data from disk,
sdkLoadPGM(outputFilename, &hOutputData, &width, &height);
printf("Comparing files\n");
printf("\toutput: <%s>\n", outputFilename);
printf("\treference: <%s>\n", refPath);
testResult = compareData(hOutputData,
hDataRef,
width*height,
MAX_EPSILON_ERROR,
0.15f);
}
checkCudaErrors(cudaFree(dData));
checkCudaErrors(cudaFreeArray(cuArray));
free(imagePath);
free(refPath);
}
3.4 实验结果和分析
实验在NVIDIA GeForce GT 550M的硬件条件下进行。本文分别实现在CPU代码和CUDA 代码,并且比较了他们在各自的执行时间,比较结果如图3.3。
在CPU 与CUDA 上的执行时间关系曲线如图3.4。
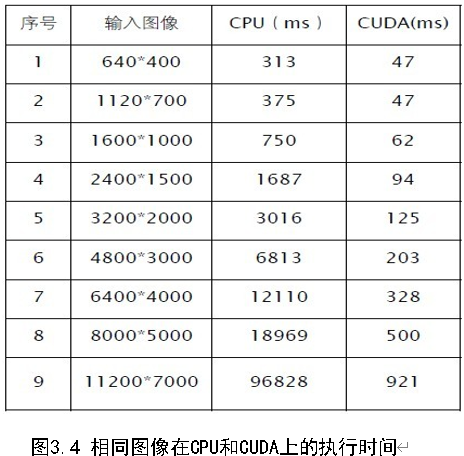
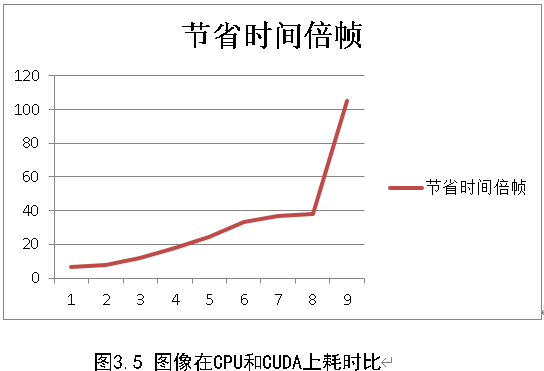
可以看出,随着处理图像尺寸逐步增加,CUDA 较CPU的相对运行时间开销明显大幅偏少,其并行计算优势显现,效率成倍提升。在输入图像为8000*5000 时,CPU的计算所花时间为CUDA计算所花时间近40倍,甚至当输入图像为11200*7000 时,CPU 所花时间为CUDA 的105 倍。这是因为在图像很小的时候,运算量并不大,加上CUDA 数据在宿主与内核之间的传送时间开销,因此还不能充分发挥出其并行计算优势。当图像质量越高的时候,数据传输量越大,CUDA在宿舍与内核之间的传送时间开销越来越大,优势也就发挥的越明显,所以,当数据量比较大的时候,CUDA可以更好的提高效率。
4 结论与展望
本文通过对基于CUDA技术的数字图像几何形变方法的实现,验证了CUDA 技术在数字图像处理领域的高效性。采用CUDA 进行并行计算,我们需要主意两点。一是每一线程处理数据分配问题。如果能找到更合理的数据数据分配算法,图像的处理效率会进一步得到提高。二是宿主设备的数据存取带宽。如何进一步提高数据的存取速度值得进一步观注。显然CUDA 为我们提供了一种超大规模并行计算方法,从硬件价格上来说比要实现同等价格所需要CPU 的价格便宜很多。从实际效果来看,CUDA 非常适合数字图像处理领域这样需要进行大量数据运算以及对实时性要求较高的领域,其效率较传统CPU计算而言不言而喻。除了图像的几何变换外,图像的边缘检测算法等都非常适合用CUDA 技术来实现。
GPU在特定的科学计算方面比CPU有更强大的运算能力,如气象和医学图像方面的相关算法,数据量都是非常大,运用CUDA的计算能力,可以很显著的提高计算速度,具有更广阔的前景。CUDA新技术为科学领域进行大规模运算提供了新的研究方法,由于GPU的特点是处理密集型数据和并行数据计算,因此CUDA非常适合需要大规模并行计算的领域。但是想要充分利用GPU的计算能力,需要将计算问题进行合理的分解以适应GPU的计算模式,发挥多级内存和大规模并行计算的优势。
参考文献
[1] Dempster A P. Upper and lower probabilities inducedby a multivalued mapping. Annals of MathematicalStatistics, 1967,38(2):325-339.
[2] Dempster A P. Generalization of Bayesian Inference.Journal of the Royal Statistical Society. Series B 30,1968:205-247.
[3] Shafer G.A Mathematical Theory of Evidence. PrincetonUniversity Press, 1976.
[4] 徐从富,耿卫东,潘云鹤.面向数据融合的DS 方法综述.电子学报, 2001,29(3):393-396.
[5] Smets P, Kennes R. The transferable belief model.Artificial Intelligence, 1994,66:191-243
[6] Voorbraak F. A computationally efficient approximationof Dempster-Shafer theory. International Journal of Man-Machine Study, 1989,30:525-536.
[7] Yen J. Generalizing the Dempster-Shafer theory tofuzzy sets. IEEE Trans. on Systems, Man, and Cybernetics,1990,20(3):559-570.
[8] 苏运霖,管纪文.证据论与约集论.软件学报, 1999,10(3):277-282.
[9] 胡昌华,司小胜,周志杰,王鹏.新的证据冲突衡量标准下的D-S 改进算法.电子学报, 2009,37(7):1578-1584.
[10] Zadeh LA. Review of Shafer’s a mathematical theoryof evidence. AI Magazine, 1984,5:81-83.
[11]李伟青.图像旋转的快速显示技术.计算机应用研究,1994,(3):13-14.
[12]张发存,王馨梅,张毅坤.数字图像几何变换的数据并行方法研究.计算机工程, 2005,31(11):159-161,196.
[13]刘振安,章守信,刘胜璞.并行图像处理算法的设计与实现.测控技术,2003,22(5):5-6.
[14] Boyer M, Skadron K, Weimer W. Automated Dynamic Analysis of CUDA Programs. STMCS 2008, Boston, Massachusetts, Apr 06, 2008
[15] Owens JD, Houston M, Luebke D, et al. GPUComputing, Proc. of the IEEE, May 2008,96(5):879-897.



")
")
常用的6种方法")
 封装运动功能")

:运行时api的使用,vs环境下的联调")




Qt Widgets Designer界面设计器和界面应用")
:if的bool判断, 变量的作用域范围, 格式字符串, 弹窗, 列表推导式, 一个点歌小程序")