少有人走的路
少有人走的路近几年来,深度学习的研究和应用的热潮持续高涨,各种开源深度学习框架层出不穷,包括TensorFlow,Keras,MXNet,PyTorch,CNTK,Theano,Caffe,DeepLearning4,Lasagne,Neon,等等。Google,Microsoft等商业巨头都加入了这场深度学习框架大战,当下最主流的框架当属TensorFlow,Keras,MXNet,PyTorch,接下来我对这四种主流的深度学习框架从几个不同的方面进行简单的对比。
一、 简介
TensorFlow:
TensorFlow是Google Brain基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理,于2015年11月9日在Apache 2.0开源许可证下发布,并于2017年12月份预发布动态图机制Eager Execution。
Keras:
Keras是一个用Python编写的开源神经网络库,它能够在TensorFlow,CNTK,Theano或MXNet上运行。旨在实现深度神经网络的快速实验,它专注于用户友好,模块化和可扩展性。其主要作者和维护者是Google工程师FrançoisChollet。
MXNet:
MXNet是DMLC(Distributed Machine Learning Community)开发的一款开源的、轻量级、可移植的、灵活的深度学习库,它让用户可以混合使用符号编程模式和指令式编程模式来最大化效率和灵活性,目前已经是AWS官方推荐的深度学习框架。MXNet的很多作者都是中国人,其最大的贡献组织为百度。
PyTorch:
PyTorch是Facebook于2017年1月18日发布的python端的开源的深度学习库,基于Torch。支持动态计算图,提供很好的灵活性。在今年(2018年)五月份的开发者大会上,Facebook宣布实现PyTorch与Caffe2无缝结合的PyTorch1.0版本将马上到来。
有关四个框架的一些基本属性的比较如表1-1所示:
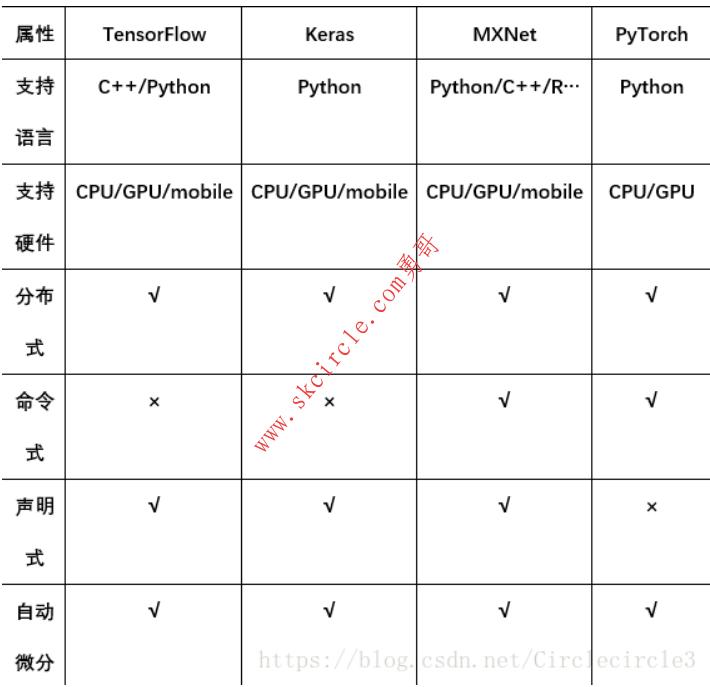
表1-1 各个框架的相关属性
二、 流行度
四个深度学习库均为开源,我们可以通过其在Github上的数据看出他们在行业中的流行程度,截止到2018年6月17日Github上数据如表2-1、表2-2所示。
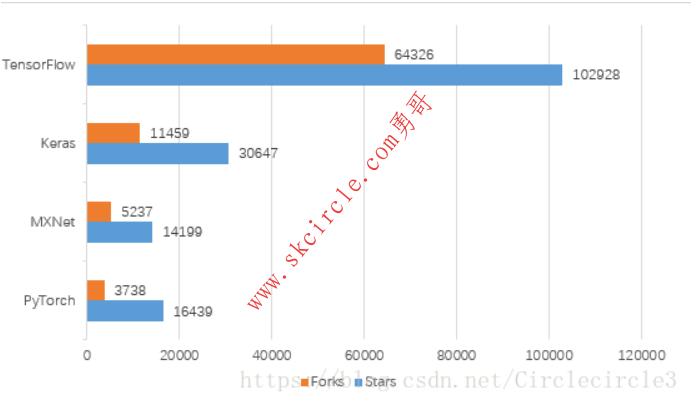
表2-1
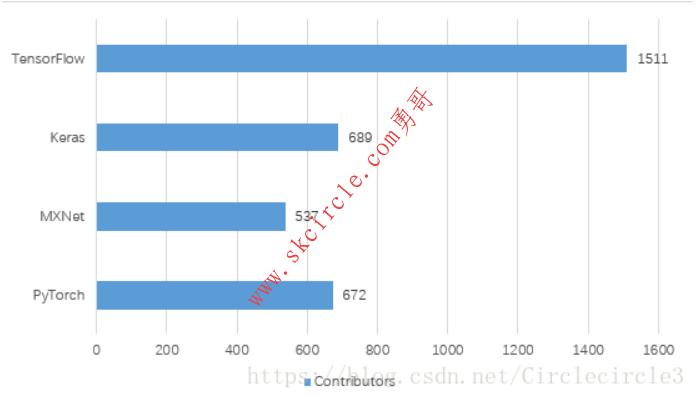
表2-2
三、 灵活性
TensorFlow主要支持静态计算图的形式,计算图的结构比较直观,但是在调试过程中十分复杂与麻烦,一些错误更加难以发。但是2017年底发布了动态图机制Eager Execution,加入对于动态计算图的支持,但是目前依旧采用原有的静态计算图形式为主。TensorFlow拥有TensorBoard应用,可以监控运行过程,可视化计算图。
Keras是基于多个不同框架的高级API,可以快速的进行模型的设计和建立,同时支持序贯和函数式两种设计模型方式,可以快速的将想法变为结果,但是由于高度封装的原因,对于已有模型的修改可能不是那么灵活。
MXNet同时支持命令式和声明式两种编程方式,即同时支持静态计算图和动态计算图,并且具有封装好的训练函数,集灵活与效率于一体,同时已经推出了类似Keras的以MXNet为后端的高级接口Gluon。
PyTorch为动态计算图的典型代表,便于调试,并且高度模块化,搭建模型十分方便,同时具备及其优秀的GPU支持,数据参数在CPU与GPU之间迁移十分灵活
四、 学习难易程度
对于深度学习框架的学习难易程度以及使用的简易度还是比较重要的,我认为应该主要基于框架本身的语言设计、文档的详细程度以及科技社区的规模考虑。对于框架本身的语言设计来讲,TensorFlow是比较不友好的,与Python等语言差距很大,有点像基于一种语言重新定义了一种编程语言,并且在调试的时候比较复杂。每次版本的更新,TensorFlow的各种接口经常会有很大幅度的改变,这也大大增加了对其的学习时间;Keras是一种高级API,基于多种深度学习框架,追求简洁,快速搭建模型,具有完美的训练预测模块,简单上手,并能快速地将所想变现,十分适合入门或者快速实现。但是学习会很快遇到瓶颈,过度的封装导致对于深度学习知识的学习不足以及对于已有神经网络层的改写十分复杂;MXNet同时支持命令式编程和声明式编程,进行了无缝结合,十分灵活,具备完整的训练模块,简单便捷,同时支持多种语言,可以减去学习一门新主语言的时间。上层接口Gluon也极其容易上手;PyTorch支持动态计算图,追求尽量少的封装,代码简洁易读,应用十分灵活,接口沿用Torch,具有很强的易用性,同时可以很好的利用主语言Python的各种优势。对于文档的详细程度,TensorFlow具备十分详尽的官方文档,查找起来十分方便,同时保持很快的更新速度,但是条理不是很清晰,教程众多;Keras由于是对于不同框架的高度封装,官方文档十分详尽,通俗易懂;MXNet发行以来,高速发展,官方文档较为简单,不是十分详细,存在让人十分迷惑的部分,框架也存在一定的不稳定性;PyTorch基于Torch并由Facebook强力支持,具备十分详细条理清晰的官方文档和官方教程。对于社区,庞大的社区可以推动技术的发展并且便利问题的解决,由Google开发并维护的TensorFlow具有最大社区,应用人员团体庞大;Keras由于将问题实现起来简单,吸引了大量研究人员的使用,具有很大的用户社区;MXNet由Amazon,Baidu等巨头支持,以其完美的内存、显存优化吸引了大批用户,DMLC继续进行开发和维护;PyTorch由Facebook支持,并且即将与Caffe2无缝连接,以其灵活、简洁、易用的特点在发布紧一年多的时间内吸引了大量开发者和研究人员,火爆程度依旧在不断攀升,社区也在不断壮大。
五、 性能
为了比较四个框架的性能(主要是运行速度),我进行了三个不同的实验,对于不同的神经网络以及不同类型的数据集在分别在CPU、GPU环境下进行了测试。
CPU环境:Ubuntu14.04 内存 32GB AMD Opteron(tm) Processor 4284
GPU环境1:Ubuntu16.04 内存 32GB Quadro P2000(5GB显存)
Intel(R) Xeon(R) CPU E5-2637 v4 @ 3.50GHz
GPU环境2:Ubuntu16.04 内存 16GB Tesla K40(12GB显存)
Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz
代码地址:https://github.com/CircleXing001/DL-tools
以下实验时间均为总训练时间,GPU环境下包括数据由内存复制到GPU的时间,不包括数据读入内存所需的时间。
实验一:基于北京pm2.5数据集的多变量时序数据预测问题
数据集:https://archive.ics.uci.edu/ml/datasets/Beijing+PM2.5+Data
模型:简单的单层LSTM+全连接层,如下图所示:
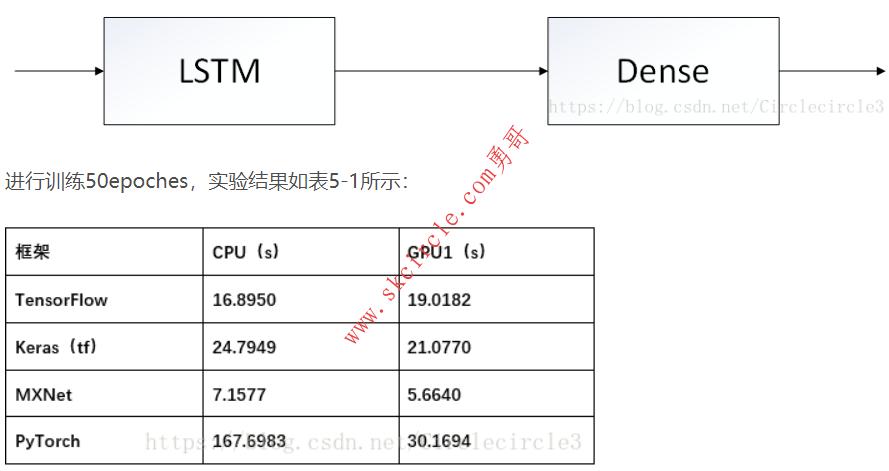
表5-1
实验二:基于Mnist数据集的分类问题
模型:两层卷积神经网络+全连接层,如下图所示:
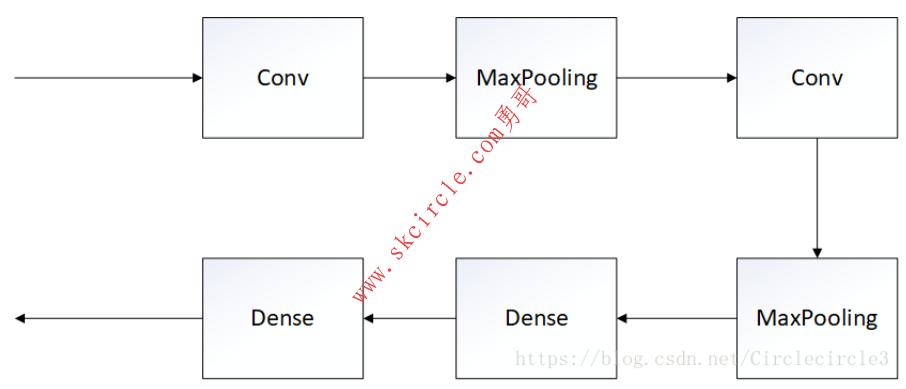
进行训练10epoches,实验结果如表5-2所示:
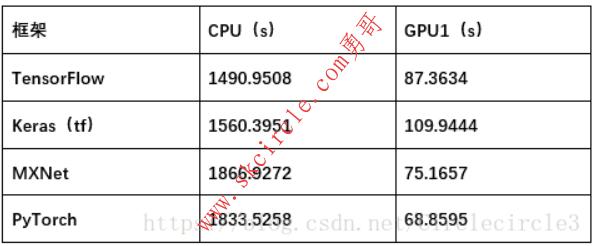
表5-2
实验三:基于DAQUAR数据集的视觉问答问题
数据集:https://www.mpi-inf.mpg.de/departments/computer-vision-and-multimodal-computing/research/vision-and-language/visual-turing-challenge/
模型:卷积神经网络+LSTM,具体如下图所示:
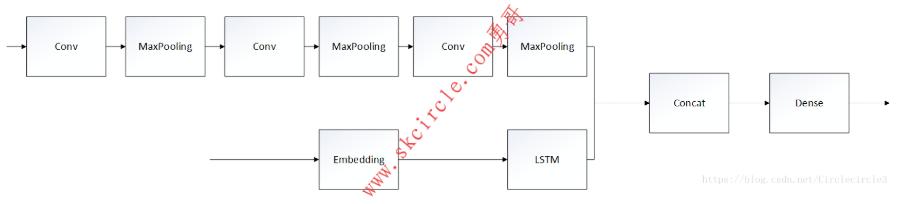
将数据缩放至50*50,进行训练5epoches,实验结果如表5-3所示:
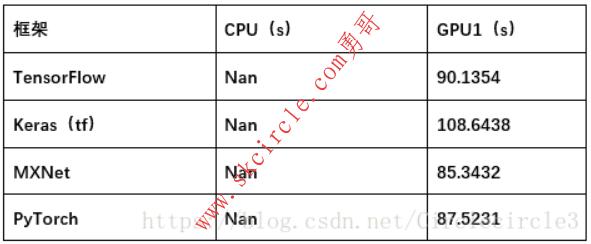
表5-3
在GPU环境2(Ubuntu16.04+内存 16GB +Tesla K40(12GB显存)+
Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz)
对上述实验三中224*224数据进行实验,对比四种框架对于硬件(GPU)的利用率,结果见表5-4。
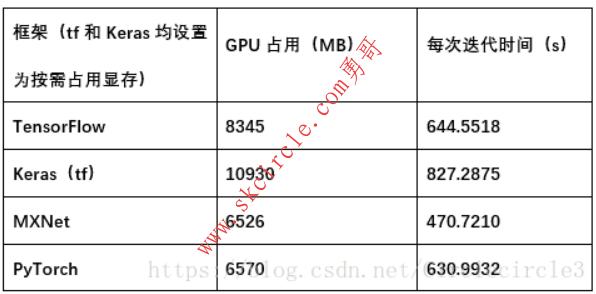
表5-4
通过上述实验我们可以发现,不同的深度学习框架对于计算速度和资源利用率的优化存在一定的差异:Keras为基于其他深度学习框架的高级API,进行高度封装,计算速度最慢且对于资源的利用率最差;在模型复杂,数据集大,参数数量大的情况下,MXNet和PyTorch对于GPU上的计算速度和资源利用的优化十分出色,并且在速度方面MXNet优化处理更加优秀;相比之下,TensorFlow略有逊色,但是对于CPU上的计算加速,TensorFlow表现更加良好。
————————————————
版权声明:本文为CSDN博主「Circle邢」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Circlecircle3/article/details/82086396
前面各位同志的回答干货不少,看了一圈受益匪浅。我也忍不住来说几句。
我就是
同志回答里说的第三类人,工业实现者。所以我这个回答是从工业界角度来讲的,至少是从我所在的公司的角度来说说。结论先说出来,在工业界TensorFlow将会比其他框架更具优势。
大家从机器学习算法研发的角度讲了很多,很多观点我也表示赞同。但是很多人忽略了重要的一点,那就是Google旗下的Android的市场份额和影响力。要知道,不管机器学习研发进行的多么火热,要转化为生产力和利润,最终需要落实到产品。目前来看,机器学习的应用归宿可粗略的划分为两类:部署于服务器端的大规模数据挖掘,为大数据服务的;另一类就是直接面向终端用户的移动端。
这两块可以说Google都不比任何人弱。首先,服务器端没什么可说的,Google拿手好戏。此外,服务器上大规模机器学习的应用各家都有自己的看家本领,比如Facebook、Twitter、Linkedin、Netflix、Amazon等等,一般各家也都有内部研发项目,用什么工具外界也不得而知,但不管怎么讲这部分毕竟数量有限,而且这些内部项目回馈开源项目的可能性较低(FB和Amazon有开源框架,但我上面说的这几个公司只是成百上千的互联网公司的一小部分,大部分用机器学习的公司事实上没有任何开源行为),因而对开源机器学习框架的格局影响不大。
而移动端,目前的需求以终端上的inference的部署为主,比如用户手机上的图像识别等应用。移动计算市场对于机器学习的需求是极其强劲的,这部分巨大的需求将会铸就一个空前规模的市场,而机器学习则是这其中不可或缺的一环。依托Android生态圈存活的不计其数的公司自然也不会放弃这个巨大的蛋糕。
在移动这一块,借助Android的巨大影响力,开发者在选择开源框架时,势必会优先选择有Google背书的TF。再加上TF标榜的“移动设备作为第一公民”的开发理念(有待于时间的检验),以及目前TF官方支持Android和iOS两大移动平台来看,选择TF将会是开发者的理性选择。此外,Google力推模型压缩和8bit低精度数据存储,除了对训练系统本身优化的作用,显然在某种程度上会使算法在移动设备上的部署收益多多,这些优化举措带来的存储需求的降低,内存带宽要求的降低,以及性能的提升,对移动设备的性能和功耗的帮助要远比在桌面或服务器系统上大的多。
简单说说移动计算这块的现状。iOS生态圈用苹果的自研SoC芯片,GPU加速靠Metal。而另一边,Android阵营芯片厂商主要有高通、三星、联发科、华为等。NVIDIA的Tegra已经明确退出移动市场(手机、平板、可穿戴设备等),转而主攻车载芯片;因此在手机端我们已经不可能看到任何设备支持CUDA。所以Android生态圈的芯片基本架构就是ARM CPU(除高通是用自己研发的处理器体系结构,各家都用的是公版ARM CPU)+ 移动GPU(高通用自研Adreno GPU,其他家大多用ARM的Mali GPU,少量Imagination的PowerVR GPU)。在Android阵营,GPU通用计算主要靠OpenCL来挑大梁(各家中/高端GPU均支持OpenCL);Google的RenderScript由于种种原因变得非常鸡肋,几乎没有开发者使用;而从Android N开始,Vulkan也会成为逐渐成为GPU通用计算的中坚力量。一句话总结下来就是,要想在Android上实现对机器学习框架的GPU加速,必须首先把机器学习框架移植到OpenCL或Vulkan上去,并且投入大量的精力针对硬件体系结构进行有针对性的优化,才有可能实现机器学习在移动平台的高效部署。
从我司视角来看,目前高通在机器学习上的战略很清楚,全力支持自己的Snapdragon Machine Learning SDK和Google的TensorFlow。为达到此目标,已经调动起SoC的所有相关部件,试图最大化的推动深度机器学习在移动设备上的应用。包括CPU、GPU(OpenCL,SYCL等)、DSP(HVX)在内的异构多核计算平台已经纷纷投入资源开始对TF进行有针对性的优化。并且从应用层面、系统硬件、甚至编译器等多方面给予支援。
此外,在工业界,还有Codeplay这样很牛的代码工厂作为partner很严肃向TF的贡献代码,推动异构平台上TF的各种实现和优化。(详见6月1日Codeplay发布的技术博客,codeplay.com 的页面)
综上,从工业界的角度来看这几大软件框架,TF的前景相对更好一点。虽然我个人很喜欢Caffe,也很敬佩各位中国学者为推动的MX做出的不懈努力,也乐于看到开源社区百花齐放的繁荣景象,但客观的从工业界的现状来看,TF背靠Google这课大树目前来看优势明显。更何况Google手中还有TPU这样的硬件,说不定它哪天急了,开卖TPU了呢(虽然可能性较小,但万事皆有可能)。广告词我都给想好了,“配合使用,效果更佳”,ヽ(^。^)丿。
作者:匿名用户
链接:https://www.zhihu.com/question/46587833/answer/104288698
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。



")
")
常用的6种方法")
 封装运动功能")
:QWidget,QMainWindow")





Qt Widgets Designer界面设计器和界面应用")
:if的bool判断, 变量的作用域范围, 格式字符串, 弹窗, 列表推导式, 一个点歌小程序")